A couple of years back, I was part of a team that delivered a workshop in machine learning. Given my background, I had been asked to do a half-day session on Regression, and was told that the standard software package being used was the scikit-learn package in python.
Both the programming language and the package were new to me, so I dug around a few days before the workshop, trying to figure out regression. Despite my best efforts, I couldn’t locate how to find out the R^2. What some googling told me was surprising:
There exists no R type regression summary report in sklearn. The main reason is that sklearn is used for predictive modelling / machine learning and the evaluation criteria are based on performance on previously unseen data
As it happened, I requested the students at the workshop to install a package called statsmodels, which provides standard regression outputs. And then I proceeded to lecture to them on regression as I know it, including significance scores, p values, t statistics, multicollinearity and the likes. It was only much later was I to figure out that that is now how regression (and logistic regression) is done in the machine learning world.
In a statistical framework, the data sets in regression are typically “long” – you have a large number of data points, and a small number of variables. Putting it differently, we start off with a model with few degrees of freedom, and then “constrain” the variables with a large enough number of data points, so that if a signal exists, and it is in the right format (linear relationship and all that), we can pin it down effectively.
In a machine learning framework, it is common to run a regression where the number of data points is of the same order of magnitude as, or even smaller than the number of variables. Strictly speaking, such a problem is unbounded (there are too many degrees of freedom), and so regression is not well-defined. Instead, we rely upon “regularisation methods” to “tie down” the variables and (hopefully) produce a consistent solution.
Moreover, machine learning approaches are common to problems where individual predictor variables don’t have meaning. In this scenario, knowing whether a particular variable is significant or not is of no utility. Then, the signal in machine learning lies in the combination of variables, which means that multicollinearity (correlation between predictor variables) is not really a bad thing as it is in statistics. Variables not having meanings means that there are no correlations per se to be defined, and so machine learning models are harder to interpret, and are more likely to have hidden spurious correlations.
Also, when you have a small number of variables and a large number of data points, it is easy to get an “exact solution” for regression, which is what statistical methods use. In a machine learning framework with “wide” data, though, exact solutions are computationally infeasible, and so you need to use approximate algorithms such as gradient descent – which are common across ML techniques.
All in all, while statistics and machine learning might use techniques with the same name (“regression”, for example), they are both in theory and practice, very different ways to solve the problem. The important thing is to figure out the approach most suited for a particular problem, and use it accordingly.


 is just one minus the above quantity (we assume that there is nothing else that can cause L(t)) .
is just one minus the above quantity (we assume that there is nothing else that can cause L(t)) .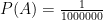
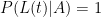
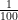 . Now,
. Now, 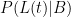 is tricky, and the reason the (t) qualifier has been added to L. The larger t is, the smaller the value of L(t)|B. If there is a bus schedule breakdown, there is probably a 50% probability that I’m not home an hour after “usual”. But there is only a 10% probability that I’m not home two hours after “usual” because a bus breakdown happened. So
is tricky, and the reason the (t) qualifier has been added to L. The larger t is, the smaller the value of L(t)|B. If there is a bus schedule breakdown, there is probably a 50% probability that I’m not home an hour after “usual”. But there is only a 10% probability that I’m not home two hours after “usual” because a bus breakdown happened. So
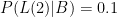


 . In other words, if I didn’t get home an hour later than usual, the odds that I had been knocked down or kidnapped was just one in five thousand!
. In other words, if I didn’t get home an hour later than usual, the odds that I had been knocked down or kidnapped was just one in five thousand!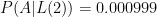 or one in a thousand! So notice that the later I am, the higher the odds that I’m in trouble. Yet, the numbers (admittedly based on the handwaving assumptions above) are small enough for us to not worry!
or one in a thousand! So notice that the later I am, the higher the odds that I’m in trouble. Yet, the numbers (admittedly based on the handwaving assumptions above) are small enough for us to not worry! .
. and
and  , the magnitude of the sum of the two vectors is given by
, the magnitude of the sum of the two vectors is given by  where
where  are the magnitudes of the two vectors respectively and
are the magnitudes of the two vectors respectively and  is the angle between them. It is easy to see from the above formula that the magnitude of the sum of the vectors is dependent not only on the magnitudes of the individual vectors, but also on the angle between them.
is the angle between them. It is easy to see from the above formula that the magnitude of the sum of the vectors is dependent not only on the magnitudes of the individual vectors, but also on the angle between them. ), then the magnitude of their vector sum is the sum of their magnitudes. If they oppose each other, then the magnitude of their vector sum is the difference of their magnitudes. And if A and B are orthogonal, then
), then the magnitude of their vector sum is the sum of their magnitudes. If they oppose each other, then the magnitude of their vector sum is the difference of their magnitudes. And if A and B are orthogonal, then 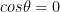 or the magnitude of their vector sum is
or the magnitude of their vector sum is 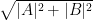 .
. ” is nothing but the correlation between A and B. And in the investing world, correlation is a fairly important and widely used concept!
” is nothing but the correlation between A and B. And in the investing world, correlation is a fairly important and widely used concept!{kind=link}