The big news of the day, as far as I’m concerned, is the victory of Google Deepmind’s AlphaZero over Stockfish, currently the highest rated chess engine. This comes barely months after Deepmind’s AlphaGo Zero had bested the earlier avatar of AlphaGo in the game of Go.
Like its Go version, the AlphaZero chess playing machine learnt using reinforcement learning (I remember doing a term paper on the concept back in 2003 but have mostly forgotten). Basically it wasn’t given any “training data”, but the machine trained itself on continuously playing with itself, with feedback given in each stage of learning helping it learn better.
After only about four hours of “training” (basically playing against itself and discovering moves), AlphaZero managed to record this victory in a 100-game match, winning 28 and losing none (the rest of the games were drawn).
There’s a sample game here on the Chess.com website and while this might be a biased sample (it’s likely that the AlphaZero engineers included the most spectacular games in their paper, from which this is taken), the way AlphaZero plays is vastly different from the way engines such as Stockfish have been playing.
I’m not that much of a chess expert (I “retired” from my playing career back in 1994), but the striking things for me from this game were
- the move 7. d5 against the Queen’s Indian
- The piece sacrifice a few moves later that was hard to see
- AlphaZero’s consistent attempts until late in the game to avoid trading queens
- The move Qh1 somewhere in the middle of the game
In a way (and being consistent with some of the themes of this blog), AlphaZero can be described as a “stud” chess machine, having taught itself to play based on feedback from games it’s already played (the way reinforcement learning broadly works is that actions that led to “good rewards” are incentivised in the next iteration, while those that led to “poor rewards” are penalised. The challenge in this case is to set up chess in a way that is conducive for a reinforcement learning system).
Engines such as StockFish, on the other hand, are absolute “fighters”. They get their “power” by brute force, by going down nearly all possible paths in the game several moves down. This is supplemented by analysis of millions of existing games of various levels which the engine “learns” from – among other things, it learns how to prune and prioritise the paths it searches on. StockFish is also fed a database of chess openings which it remembers and tries to play.
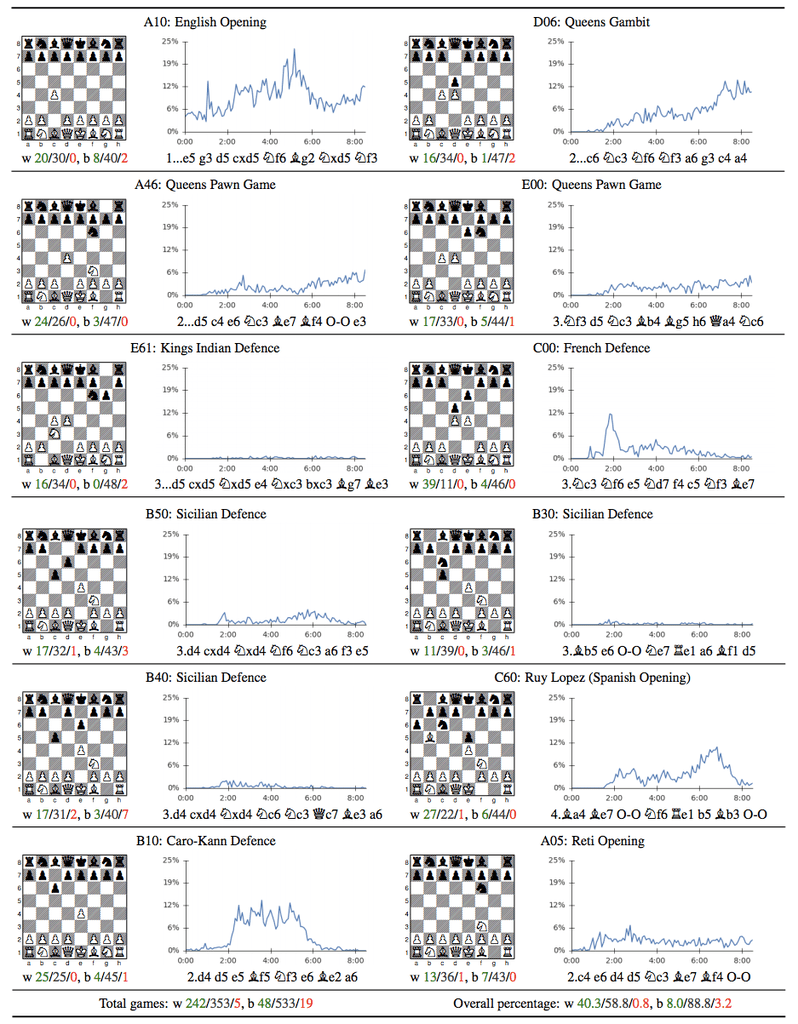
What is interesting is that AlphaZero has “discovered” some popular chess openings through the course of is self-learning. It is interesting to note that some popular openings such as the King’s Indian or French find little favour with this engine, while others such as the Queen’s Gambit or the Queen’s Indian find favour. This is a very interesting development in terms of opening theory itself.
In any case, my immediate concern from this development is how it will affect human chess. Over the last decade or two, engines such as stockfish have played a profound role in the development of chess, with current top players such as Magnus Carlsen or Sergey Karjakin having trained extensively with these engines.
The way top grandmasters play has seen a steady change in these years as they have ingested the ideas from engines such as StockFish. The game has become far more quiet and positional, as players seek to gain small advantages which steadily improves over the course of (long) games. This is consistent with the way the engines that players learn from play.
Based on the evidence of the one game I’ve seen of AlphaZero, it plays very differently from the existing engines. Based on this, it will be interesting to see how human players who train with AlphaZero based engines (or their clones) will change their game.
Maybe chess will turn back to being a bit more tactical than it’s been in the last decade? It’s hard to say right now!