There is a traditional way of allotting shirt numbers to football players. “Back to front, right to left”, goes the rule. The goalkeeper is thus number 1. Irrespective of the system used, the right back is number 2, and usually the left forward/winger is number 11.
Now, the way different teams allot numbers depends upon their historical formations, and how their current formations have evolved from those historical formations. The two historical formations that are the 2-3-5 (mostly played in Europe) and the W-M (which originated in South America).
You can read Jonathan Wilson’s excellent Inverting the Pyramid to find more about how formations evolved. This post, however, is about shirt numbers in the ongoing world cup.
Now, given the way numbering has evolved in different countries, each number (between 1 and 11) has a traditional set of roles involved. 1 is the goalie everywhere, 2 is right back everywhere. 3 is left back in Europe, but right centre back in South America. 4 is central midfielder in England, but centre back in Spain and South America. 6 is a central defender in England, left back in Brazil/Argentina and a midfielder in Spain.
These are essentially numbering conventions based on how numbering systems have evolved, but are seldom a rule. However, such conventions are so ingrained in the traditional football watcher’s mind that when a player wears a shirt number that is not normally associated with his position, it appears “wrong”.
For example, William Gallas, a centre back (and occasional right back for Chelsea) by trade moved to Arsenal in 2006 and promptly got the number 10 shirt, which is usually reserved for a central attacker/attacking midfielder (in fact, the number now defines the role – it is simply called the “number 10 role”). In the last season, West Ham used two successive left backs (Razvan Rat and Pablo Armero) last season, and both were allotted number 8 – traditionally allocated to a central midfielder.
In this post, we will look at the squads of the ongoing world cup and try and understand how many players are wearing “wrong” shirt numbers. In order to do this, we look at the most common roles associated with a particular number, and identify any players that don’t fit this convention.
Figures 1 and 2 have the summary of the distribution of roles according to shirt number.


As we can see, all number 1s are goalkeepers (perhaps there is a FIFA rule to this effect). Most number 2s and 3s are defenders, but there is the odd midfielder and forward also who wears this. Iranian forward Khosro Heydari wears 2, as do Greek midfielder Ioannais Maniatis and Bosnian midfielder Avdija Vrsajevic.
The most unnatural number 3 (in his defence, he’s always worn 3) is Ghanaian striker Asamoah Gyan. Iranian midfielder Ehsan Aji Safi also wears a 3, contrary to convention.
As discussed earlier, midfielders from a few countries wear 4, but there are also two forwards who wear that number – Japanese Keisuke Honda and Australian Tim Cahill. This can be explained by the fact that both of them started off as midfielders, and then turned into forwards, but perhaps wanted to keep their original numbers.
5 is split entirely between defenders and midfielders, who also make up for most of the number 6s. The one exception to this is Russia’s Maksim Kanunnikov, who is a forward. Interestingly, as many as six number 7s (associated with a right winger in both 2-3-5 and W-M systems) are listed as defenders! This includes Colombia’s left back Armero who notoriously wore 8 for West Ham last year. This might possibly be explained by players who started off as wingers and then moved back, but kept their numbers. Two defenders – Costa Rica’s Heiner Mora and Australia’s Bailey Wright wear number 8.
Number 9 is again one of those numbers which is associated with a specific role – a centre forward. In fact, in recent times, there is a variation of this called the “false nine” (there is also a “false ten” now). We would thus expect that all number nines are number nines, but a few midfielders also get that number. Prominent among those is Newcastle’s Cheick Tiote, who wears 9 for Cote D’Ivoire.
10 is split between midfielders and forwards (as expected), but a few defenders wear 11. Croatian captain and right back Darijo Srna wears 11, as also does Greek defender Loukas Vyntra.
Beyond 11, there is no real convention in terms of shirt numbering. The only interesting thing is in the numbers allotted to the reserve goalkeepers (notice that no goalies take any number between 2 and 11). By far, 12 is the most popular number allotted to the reserve goalkeeper, but some teams use 13 as well. Then, 22 and 23 are also pretty popular numbers for goalkeepers.
Finally, we saw that Iran was the culprit in allocating numbers 2 and 3 to non-defenders. Greece, too, came up as a repeat offender in terms of allocating inappropriate numbers. Can we build a “number convention index” and see which countries deviated most from the numbering conventions?
Now, there are degrees in being unconventional, and these need to be accommodated into the analysis. For example, a midfielder wearing 4 (there are 6 of them) is pretty normal, but a forward wearing 3 is simply plain wrong. A forward wearing 8 is not “correct”, but not “wrong” either – this shows that we need more than a simple binary scoring system.
What we will do is to first identify the most common player type for each number, and every such player will get a score of 1. For every other player wearing that number, the score will be the number of such players wearing that number divided by the number of players wearing that number who occupy the most popular position for that number.
I’m assuming the last paragraph didn’t make sense so let me use an example. To use number 2, the most popular position for a number 2 is in defence, so every defender who wears 2 gets 1 point. There are two defenders who wear 2, compared to 29 defenders who wear 2. Thus, each defender who wears 2 gets 2/29 points. One forward wears 2, and he gets 1/29 point.
Taking number 10, the most common position for the number is forward (there are 17 of them), and they all get 1 point. The remaining 15 players who wear 10 are all midfielders, and they get 15/17 points (notice this is not so much less than 1).
This way, each member of each squad gets allotted points based on how “normal” his shirt number is given his position. Summing up the points across players of a team, we get a team score on how “natural” the shirt numbers are. The maximum score a team can get is 23 (each player wearing a number appropriate for his position).
Table 3 here has the team-wise information on correctness of shirt numbers. The team with the worst allocated shirt numbers happens to be Nigeria with 16.13. At the other end, the team that has allocated numbers most appropriately is Ecuador, with 21.
| Country | Score |
| Nigeria | 16.13 |
| Costa Rica | 16.85 |
| Greece | 17.22 |
| Australia | 17.45 |
| Iran | 17.69 |
| Ivory Coast | 17.74 |
| Colombia | 18.19 |
| Cameroon | 18.19 |
| Argentina | 18.29 |
| USA | 18.41 |
| Italy | 18.63 |
| Portugal | 18.66 |
| Algeria | 18.68 |
| Honduras | 18.69 |
| France | 19.02 |
| Ghana | 19.06 |
| Croatia | 19.08 |
| Netherlands | 19.20 |
| Mexico | 19.23 |
| Brazil | 19.28 |
| Chile | 19.37 |
| Japan | 19.52 |
| South Korea | 19.69 |
| England | 19.77 |
| Russia | 20.03 |
| Switzerland | 20.04 |
| Uruguay | 20.25 |
| Spain | 20.27 |
| Bosnia & Herzegovina | 20.37 |
| Belgium | 20.83 |
| Germany | 20.86 |
| Ecuador | 21.01 |
This, however, may not tell the complete story. As we saw earlier, conventions regarding numbers between 12 and 23 are not as strict, and thus these numbers can get allocated in a more random fashion compared to 1-11. There are absolutely no taboos related to numbers 12-23, and thus, misallocating them is less of a crime than misallocating 1-11.
Hence, we will look at the numbers 1 to 11, and see how teams have performed. Table 4 has this information:
| Country | Score |
| Australia | 7.45 |
| USA | 8.04 |
| Iran | 8.18 |
| Greece | 8.59 |
| Nigeria | 8.63 |
| Ivory Coast | 8.71 |
| Costa Rica | 8.84 |
| Ghana | 8.95 |
| Croatia | 8.96 |
| Japan | 9.06 |
| Colombia | 9.27 |
| Brazil | 9.29 |
| Spain | 9.66 |
| Bosnia & Herzegovina | 9.67 |
| Uruguay | 9.70 |
| Honduras | 9.71 |
| Portugal | 9.78 |
| Italy | 9.81 |
| South Korea | 9.83 |
| Cameroon | 9.83 |
| Chile | 9.87 |
| Russia | 9.94 |
| England | 9.97 |
| Argentina | 10.03 |
| Switzerland | 10.18 |
| Netherlands | 10.24 |
| Algeria | 10.30 |
| Ecuador | 10.34 |
| Mexico | 10.35 |
| France | 10.53 |
| Belgium | 10.88 |
| Germany | 11.00 |
Germany has a “perfect” first eleven, in terms of number allocation. Belgium comes close. At the other end of the scale, we have Australia, which seems to have the most misallocated 1-11 shirt numbers. Iran and Greece, which we anecdotally saw as having high misallocations are at three and four, with the United States at 2.
Note: The data is taken from the Guardian Data Blog. Now, this analysis should be taken with some salt since in the modern game, the division of players into “defender”, “midfielder” and “forward” is not straightforward. Where would you put a “classic number ten”? What about a wing back? And so forth.








 be
be 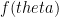 . Now, we can argue that this is a super-linear function. That is, if
. Now, we can argue that this is a super-linear function. That is, if  is also strictly increasing.
is also strictly increasing.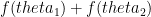 . If the total angle available is
. If the total angle available is  , then the goalkeeper needs to minimize
, then the goalkeeper needs to minimize 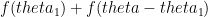 . Taking first derivative and equating it to zero we get,
. Taking first derivative and equating it to zero we get,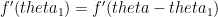
 or
or  or
or 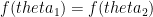 .
.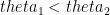 , and thus increases the overall chance of getting beaten.
, and thus increases the overall chance of getting beaten.