The economist in me will give a very simple answer to that question – it depends. It depends on how long you think people will take from onset of the disease to die.
The modeller in me extended the argument that the economist in me made, and built a rather complicated model. This involved smoothing, assumptions on probability distributions, long mathematical derivations and (for good measure) regressions.. And out of all that came this graph, with the assumption that the average person who dies of covid-19 dies 20 days after the thing is detected.

Yes, there is a wide variation across the country. Given that the disease is the same and the treatment for most people diseased is pretty much the same (lots of rest, lots of water, etc), it is weird that the case fatality rate varies by so much across Indian states. There is only one explanation – assuming that deaths can’t be faked or miscounted (covid deaths attributed to other reasons or vice versa), the problem is in the “denominator” – the number of confirmed cases.
What the variation here tells us is that in states towards the top of this graph, we are likely not detecting most of the positive cases (serious cases will get themselves tested anyway, and get hospitalised, and perhaps die. It’s the less serious cases that can “slip”). Taking a state low down below in this graph as a “good tester” (say Andhra Pradesh), we can try and estimate what the extent of under-detection of cases in each state is.
Based on state-wise case tallies as of now (might be some error since some states might have reported today’s number and some mgiht not have), here are my predictions on how many actual number of confirmed cases there are per state, based on our calculations of case fatality rate.
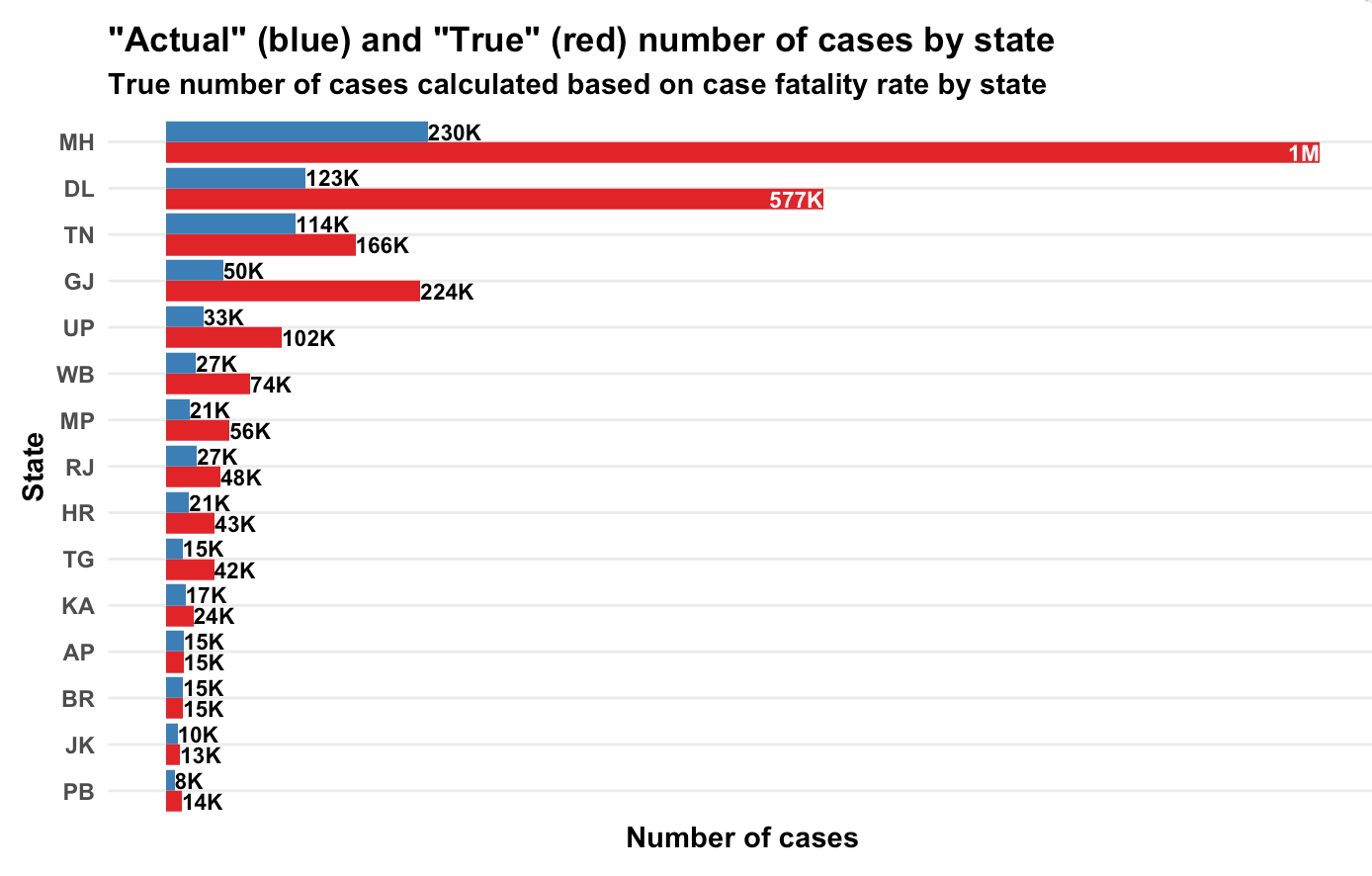
Yeah, Maharashtra alone should have crossed a million caess based on the number of people who have died there!
Now let’s get to the maths. It’s messy. First we look at the number of confirmed cases per day and number of deaths per day per state (data from here). Then we smooth the data and take 7-day trailing moving averages. This is to get rid of any reporting pile-ups.
Now comes the probability assumption – we assume that a proportion 


My maths has become rather rusty over the years but a derivation I made shows that 
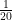
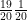
So people who die today could be people who were detected with the infection yesterday, or the day before, or the day before day before (isn’t it weird that English doesn’t a word for this?) or … Now, based on how many cases were detected on each day, and our assumption of 
The equation will look something like this. Assume 


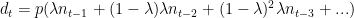
Now, all these 
And we have this data for multiple days. We know the left hand side. We know the value in brackets on the right hand side. All we need to do is to find
And I did this for each state – take the number of confirmed cases on each day, the number of deaths on each day and your assumption on average number of days after detection that a person dies. And you can calculate
This produced the first graph that I’ve presented above, for the assumption that a person, should he die, dies on an average 20 days after the infection is detected.
So what is India’s case fatality rate? While the first graph says it’s 5.8%, the variations by state suggest that it’s a mild case detection issue, so the true case fatality rate is likely far lower. From doing my daily updates on Twitter, I’ve come to trust Andhra Pradesh as a state that is testing well, so if we assume they’ve found all their active cases, we use that as a base and arrive at the second graph in terms of the true number of cases in each state.
PS: It’s common to just divide the number of deaths so far by number of cases so far, but that is an inaccurate measure, since it doesn’t take into account the vintage of cases. Dividing deaths by number of cases as of a fixed point of time in the past is also inaccurate since it doesn’t take into account randomness (on when a Romeo might die).
Anyway, here is my code, for what it’s worth.
deathRate <- function(covid, avgDays) {
covid %>%
mutate(Date=as.Date(Date, '%d-%b-%y')) %>%
gather(State, Number, -Date, -Status) %>%
spread(Status, Number) %>%
arrange(State, Date) ->
cov1
# Need to smooth everything by 7 days
cov1 %>%
arrange(State, Date) %>%
group_by(State) %>%
mutate(
TotalConfirmed=cumsum(Confirmed),
TotalDeceased=cumsum(Deceased),
ConfirmedMA=(TotalConfirmed-lag(TotalConfirmed, 7))/7,
DeceasedMA=(TotalDeceased-lag(TotalDeceased, 7))/ 7
) %>%
ungroup() %>%
filter(!is.na(ConfirmedMA)) %>%
select(State, Date, Deceased=DeceasedMA, Confirmed=ConfirmedMA) ->
cov2
cov2 %>%
select(DeathDate=Date, State, Deceased) %>%
inner_join(
cov2 %>%
select(ConfirmDate=Date, State, Confirmed) %>%
crossing(Delay=1:100) %>%
mutate(DeathDate=ConfirmDate+Delay),
by = c("DeathDate", "State")
) %>%
filter(DeathDate > ConfirmDate) %>%
arrange(State, desc(DeathDate), desc(ConfirmDate)) %>%
mutate(
Lambda=1/avgDays,
Adjusted=Confirmed * Lambda * (1-Lambda)^(Delay-1)
) %>%
filter(Deceased > 0) %>%
group_by(State, DeathDate, Deceased) %>%
summarise(Adjusted=sum(Adjusted)) %>%
ungroup() %>%
lm(Deceased~Adjusted-1, data=.) %>%
summary() %>%
broom::tidy() %>%
select(estimate) %>%
first() %>%
return()
}