So Nitin Pai and Pranay Kotasthane have a great graphic on how India should react to China’s aggressions on Doka La. While the analysis is excellent, my discomfort is with the choice of “deltas” as the axes of this payoff diagram, rather than levels.
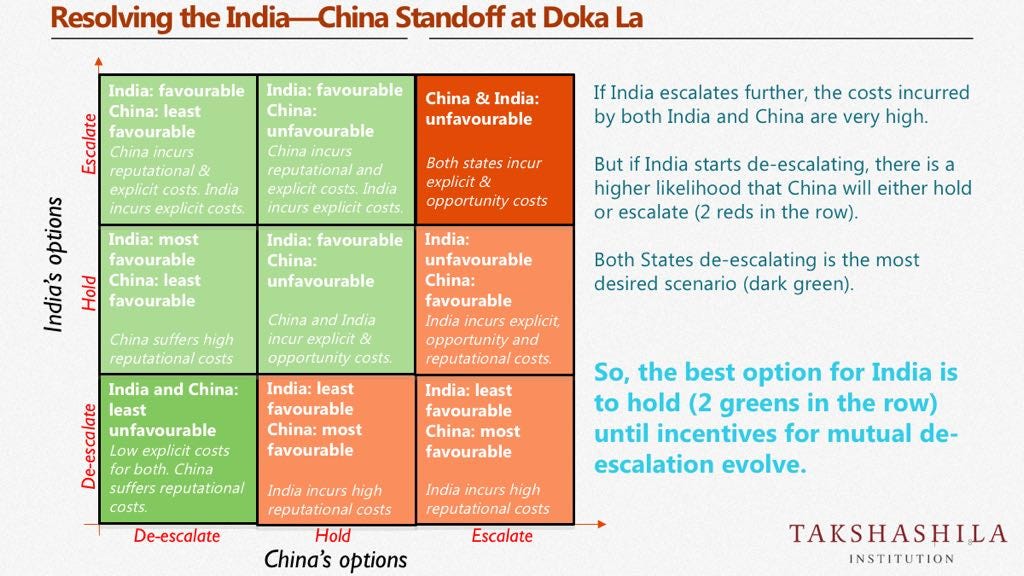
Instead, what might have been preferable would have been to define each countries strategies in terms of levels of aggressions, define their current levels of aggression, and evaluate the two countries’ strategies in terms of moving to each possible alternate level. Here is why.
The problem with using shifts (or “deltas” or “slopes” or whatever you call the movement between levels) is that they are not consistent. Putting it mathematically, the tangent doesn’t measure the rate of change in a curve when you go far away from the point where you’ve calibrated the tangent.
To illustrate, let’s use this diagram itself. The strategy is that India should “hold”. From the diagram, if India holds, China’s best option is to escalate. In the next iteration, India continues to hold, and China continues to escalate. After a few such steps, surely we will be far away enough from the current equilibrium that the payoff for changing stance is very different from what is represented by this diagram?
This graph is perhaps valid for the current situation where (say) India’s aggression level is at 2 on a 1–5 integer scale, while China is at 3. But will the payoffs of going up and down by a notch be the same if India is still at 2 and China has reached the maximum pre-war aggression of 5 (remember that both are nuclear powers)?
On the flip side, the good thing about using payoffs based on changes in level is that it keeps the payoff diagram small, and this is especially useful when the levels cannot be easily discretised or there are too many possible levels. Think of a 5×5 square graph, or even a 10×10, in place of the 3×3, for example?—?soon it can get rather unwieldy. That is possibly what led Nitin and Pranay to choose the delta graph.
Mirrored here.
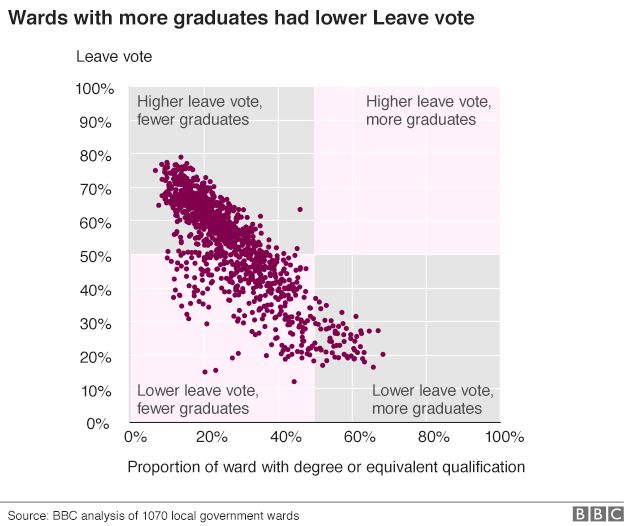
 next to the line, to show the extent of correlation!
next to the line, to show the extent of correlation!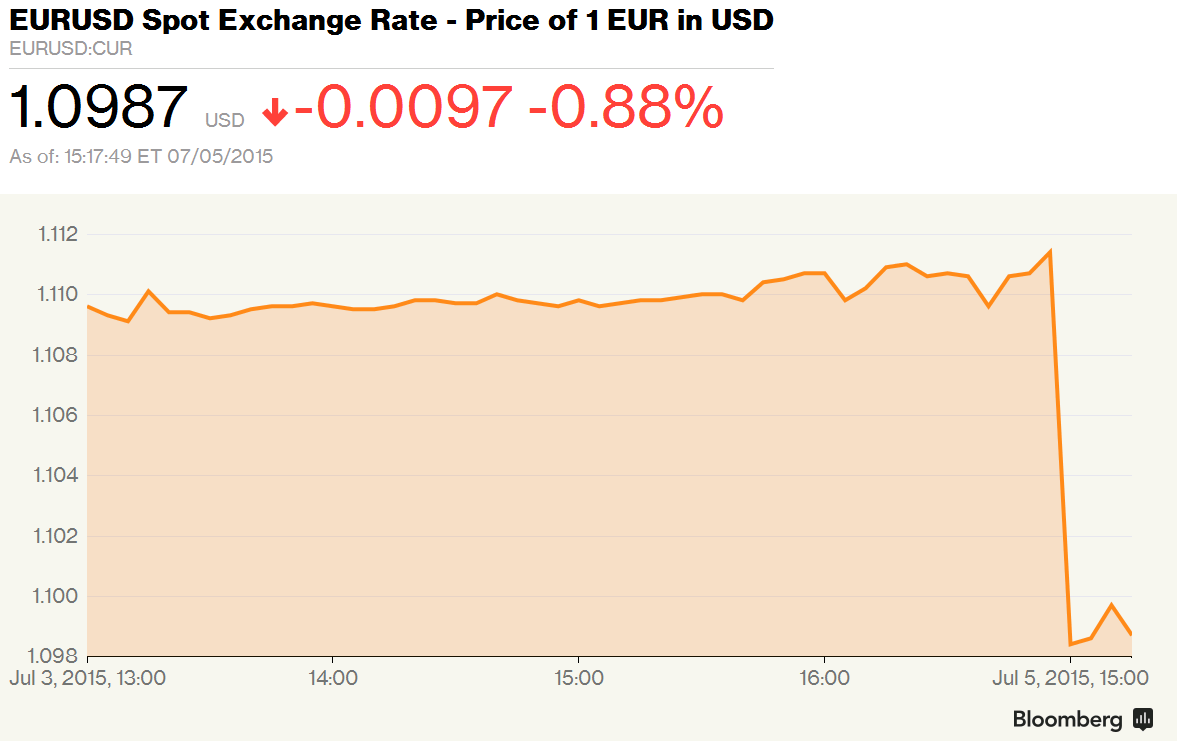 You notice the spectacular drop right? Cliff-like. You think the Euro is doomed now that the Greeks have voted “no”? Do not despair, for all you need to do is to look at the axis, and the axis labels.
You notice the spectacular drop right? Cliff-like. You think the Euro is doomed now that the Greeks have voted “no”? Do not despair, for all you need to do is to look at the axis, and the axis labels.


