The Guardian has an interesting set of graphics trying to identify the “Group of Death” at the forthcoming (2014) football World Cup. They have basically ordered groups and teams on three counts – something called as “strength of schedule” (how it is calculated is not explained), average strength of each group (mean rating points) and the strength of each match (sum total of rating points of the teams playing). They don’t actually go on to identify which the groups of death are.
Another piece in the same paper gives a history of the concept of the Group of Death, and tries to explain why some groups can be classified so while others cannot. So in this post we will focus on precisely that – once a draw has been made, how do we identify groups of death? Without loss of generality, let us restrict our analysis to groups of four teams from which two qualify for the next round following a round robin (the format the World Cup uses). We will also restrict ourselves to analyzing the group stage and ignore chances of “death” in the knockout stages.
A “group of death” traditionally refers to a group where at least one “favourite” team gets knocked out. Assuming that a team with higher odds of winning the tournament is likely to beat one with lower odds, a group of death is necessarily one that contains at least three teams that are “favourites” to win the tournament.
From this, one way to measure groups of death is to order teams in decreasing order of odds of winning based on a reputed bookie’s odds, and then see how closely the top three teams of a group are clustered. The closer three teams are to each other, the closer the group is. We can use a distance metric to measure this.
Another simpler method is to see the odds of the third team in a group winning the world cup. The groups where the third best odds of winning are the groups of death! Again this is a relative metric since if each group has two “strong teams” and two “weak teams” there is effectively no group of death (hence the earlier metric trumps this one).
Another way to identify how deadly the groups are is to use bilateral odds for each match, and to identify the odds that the two “seeded teams” in a group both don’t qualify. For example, Group B has Spain, Netherlands, Australia and Chile, with the first two being the “seeded teams” (given their ranking). Now, we can calculate the probability that at least one of Spain and Netherlands doesn’t qualify. That gives the “death rating” for this group. The group for which this “death rating” is highest is the group of death.
As you can see, there are several ways for identifying the group of death. Unfortunately, none of the analysis that the Guardian has put out contributes to this. Let us now look at a couple of methods for ourselves. For the purpose of analysis I’m using the easiest available odds, which are from the Bleacher Report. Ideally, for this analysis we should be using odds before the draw was made – since the draw itself would have ended up adjusting odds. Nevertheless, since this is for illustrative (rather than predictive) purposes only, we’ll stick to the current odds.
Let us start with the easiest method, which is the odds of victory of the third best team in the group. Based on the Bleacher odds, the third best teams in each group are likely to be :
A Mexico 150/1
B Chile 33/1
C Japan 150/1
D England 28/1
E Ecuador 150/1
F Nigeria 250/1
G United States 150/1
H South Korea 150/1
Two teams stand out – Chile at 33/1 and England at 28/1. Based on this metric, the group of death is Group D (Italy, England, Uruguay, Costa Rica). The Guardian might say that Australia, Ghana or the United States might have the toughest draw, but the odds of each of them winning is so low that it doesn’t matter that they have tough draws!
Let us now use another metric – the difference between the odds of the second and third placed teams in each group. One metric of the group of death might be where this difference is the minimum (this metric has the problem of classifying groups with one clear winner as groups of death, while they technically are not).
And this metric identifies Group F (Bosnia, Nigeria) and Group A (Croatia, Mexico) as groups of death. You might notice that these are Argentina and Brazil’s groups respectively and those two teams are expected to sail through, so this is not a good metric.
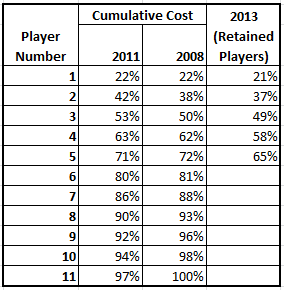
Next, let us involve the top three teams of each group (to prevent the above anomaly) and look at the sum of the absolute difference in odds. For example, if the odds of the top three teams in a group are o1, o2, o3, we will measure each group by (|o1-o2| + |o2-o3| + |o3-o1|). The smaller this sum is, the more likely a group is a “group of death”.
The results from this metric are below:
A 42% Brazil, Croatia, Mexico
B 16% Spain, Netherlands, Chile
C 7% Colombia, Japan, Greece
D 0.7% Uruguay, Italy, England
E 7% Switzerland, France, Ecuador
F 27% Argentina, Bosnia, Nigeria
G 23% Germany, Portugal, United States
H 10% Belgium, Russia, South Korea.
From this metric, it is absolutely clear which the most competitive group is – it is group D, with Uruguay, Italy and England. Based on this metric, it is unambiguous that Group D is the group of death. Groups C and E come next according to this measure, followed by Group H.








 be
be 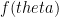 . Now, we can argue that this is a super-linear function. That is, if
. Now, we can argue that this is a super-linear function. That is, if  is also strictly increasing.
is also strictly increasing.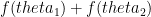 . If the total angle available is
. If the total angle available is  , then the goalkeeper needs to minimize
, then the goalkeeper needs to minimize 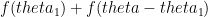 . Taking first derivative and equating it to zero we get,
. Taking first derivative and equating it to zero we get,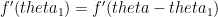
 or
or  or
or 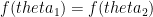 .
.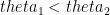 , and thus increases the overall chance of getting beaten.
, and thus increases the overall chance of getting beaten.



