I have mentioned multiple times here before that I love Instagram advertising. I love that whatever Instagram learns from my likes (and not likes) on the platform, and through the various pixels that Facebook leaves all over the interwebs, gets used in showing me highly relevant advertising.
Rather, ever since I started using Instagram, I loved the advertising for its visual quality (that made it hard to distinguish if it was an advertisement or native content), and as things have gotten more relevant over time, I’ve started clicking through. And as I’ve started clicking occasionally, the advertising has become more relevant.
I’m sure some silicon valley marketer has some imagery about flywheels. I’m reminded of that hamster spinning this wheel when I’d gone to this animal farm near Bangalore last year.
In any case, I read this article about “the hard thing about easy things“. The basic theory, if I understand it right, is that by commoditising all the tools of production when it comes to direct to consumer selling, the business of direct to consumer selling has gotten that much harder.
The article goes on to say that unless the brand has a competitive advantage in manufacturing (or sourcing by any other means), it is pretty much impossible to make money off direct to consumer products – you struggle to repel the attack of the clones, and you have to spend increasing amounts of money on online marketing (through Google and Facebook).
While this makes sense (or not?) from an investment and entrepreneurship perspective, it got me wondering – as a consumer, how can I distinguish the quality direct to consumer products from those that have somehow simply managed to get into my feed?
Some advertising is like a peacock’s tail – it doesn’t signal any direct value about the brand being advertised. However, it signals that if the brand can afford to spend such huge amounts of money on this form of advertising, it ought to be a brand with sufficient spare cash flow that it is a good brand.
For example, when Vivo got title sponsorship of the IPL, it not only created awareness (which possibly existed thanks to its retail stores and advertising on Amazon) but also signalled that it is a “good brand” since it had bought prime advertising real estate.
Similarly, when a brand advertises on the SuperBowl, the actual dollars per eyeball may not make sense. However, when you add in the signalling value of having been there on SuperBowl (“if a brand can afford to advertise on SuperbOwl, it ought to be a good brand”), it starts making sense.
This works with a lot of mass media advertising. Front page of Times of India is premium because of peacock’s tail. Advertising in the IPL for the same reason. Perhaps similar with hoardings on the way out of airports. And booking prime time slots on popular television shows.
The problem with online advertising is that it is so targeted (and algorithmic) that this signalling effect goes away. Your instagram feed is like the Times of India where every page is similar to every other page.
From that perspective, it is hard to determine whether an advertisement represents a quality product when it appears on your Instagram timeline.
I bought Vahdam tea after someone recommended it to me on Twitter. I bought Paul and Mike’s chocolates after a friend wrote her appreciation for it on Instagram. When I started buying Blue Tokai coffee, I needed good coffee powder and was in the mood for exploration, but was helped by multiple friends and acquaintances vouching for it .
Marketing solely using digital means runs into this problem of not having the signalling effect. And that means you need to invest in “social” also, however you can imagine that to be. Then again, people have started seeing through “influencers”, like how they started seeing through “endorsements” a generation ago.
There was a tiny controversy on one WhatsApp group I’m part of. This is a “sparse” WhatsApp group, which means there aren’t too many messages sent. Only around 1000 in nearly 5 years (you’ll soon know how I got that number).
And this morning I wake up to find 42 messages (many members of the group are in the US). Some of them I understood and some I didn’t. So the gossip-monger I am (hey, remember that Yuval Noah Harari thinks gossip is the basis of human civilisation?), I opened up half a dozen backchannel chats.
Like the six blind men of Indostan, these chats helped me construct a picture of what had happened. My domain knowledge had gotten enhanced. However, there was one message that had made a deep impression on me – that claimed that some people were monopolising whatever little conversation there was on that group.
I HAD to test that hypothesis.
The jobless guy that I am, I figured out how to export a chat from WhatsApp. With iOS, it’s rather easy. Go to the info page of a chat or a group, and near “delete chat/group”, you see “export chat/group”. If you say you don’t want media (like I did), you get a text file (I airdropped mine immediately into my Mac).
The formatting of the WhatsApp export file is rather clean, making it easy to parse. The date is in square brackets. The sender’s name (or number, if they’re not in your contact list) is before a colon after the square brackets. A couple of “separate” functions later you are good to go (there are a couple of other nuances. If you can read R code, check mine here).
chat <- read_lines('~/Downloads/_chat.txt')
tibble(txt=chat) %>%
separate(txt, c("Date", "Content"), '\\] ') %>%
separate(Content, c("Sender", "Content"), ': ') %>%
mutate(
Content=coalesce(Content, Date),
Date=str_trim(str_replace_all(Date, '\\[', '')),
Date2=as.POSIXct(Date, format='%d/%m/%y, %H:%M:%S %p')
) %>%
fill(Date2, .direction = 'updown') %>%
fill(Sender, .direction = 'downup') %>%
filter(!str_detect(Sender, "changed their phone number to a new number") ) %>%
filter(!str_detect(Sender, ' added ') & !str_detect(Sender, ' left')) %>%
filter(!str_detect(Sender, " joined using this group's invite link"))->
mychat
That’s it. You are good to go. You have a nice data frame with sender’s name, message content and date/time of sending. And as one of the teachers at my JEE coaching factory used to say, you can now do “gymnastics”.
And so for the last hour or so I’ve been wasting my time doing such gymnastics. Number of posts sent on each day. Testing the hypothesis that some people talk a lot on the group (I turned out to be far more prolific than I’d imagined). People who start conversations. Whether there are any long bilateral conversations on the group. And so on and so forth (this is how I know there are ~1000 messages on this group).
Now I want to subject all my conversations to such analysis. For bilaterals it won’t be that much fun – but in case there is some romantic or business interest involved you might find it useful to know who initiates more and who closes more conversations.
You can subject the conversations to natural language processing (with what objective, I don’t know). The possibilities are endless.
And the time wastage can be endless as well. So I’ll stop here.
Legendary retailer John Wanamaker (who pioneered fixed price stores in the mid 1800s) is supposed to have said that “half of all advertising is useless. The trouble is I don’t know which half”.
I was playing around with my twitter archive data, and was looking at the distribution of retweets and favourites across all my tweets. To say that it follows a power law is an understatement.
Before this blog post triggers an automated tweet, I have 63793 tweets, of which 59,275 (93%) have not had a single retweet. 51,717 (81%) have not had a single person liking them. And 50, 165 (79%) of all my tweets have not had a single retweet or a favourite.
In other words, nearly 80% of all my tweets had absolutely no impact on the world. They might as well have not existed. Which means that I should cut down my time spent tweeting down to a fifth. Just that, to paraphrase Wanamaker, I don’t know which four fifths I should eliminate!
There is some good news, though. Over time, the proportion of my tweets that has no impact (in terms of retweets or favourites – the twitter dump doesn’t give me the number of replies to a tweet) has been falling consistently.
Right now, this month, the score is around 33% or so. So even though the proportion of my useless tweets have been dropping over time, even now one in every tweets that I tweet has zero impact.
My “most impactful tweet” itself account for 17% of all retweets that I’ve got. Here I look at what proportion of tweets have accounted for what proportion of “reactions” (reactions for each tweet is defined as the sum of number of retweets and number of favourites. I understand that the same person might have been retweeted and favourited something, but I ignore that bit now).
Notice how extreme the graph is. 0.7% of all my tweets have accounted for 50% of all retweets and likes! 10% of all my tweets have accounted for 90% of all retweets and likes.
Even if I look only at recent data, it doesn’t change shape that much – starting from January 2019, 0.8% of my tweets have accounted for 50% of all retweets and likes.
This, I guess, is the fundamental nature of social media. The impact of a particular tweet follows a power law with a very small exponent (meaning highly unequal).
What this also means is that anyone can go viral. Anyone from go from zero to hero in a single day. It is very hard to predict who is going to be a social media sensation some day.
So it’s okay that 80% of my tweets have no traction. I got one blockbuster, and who knows – I might have another some day. I guess such blockbusters is what we live for.
It was early on in the lockdown that the daughter participated in her first ever Zoom videoconference. It was an extended family call, with some 25 people across 9 or 10 households.
It was chaotic, to say the least. Family call meant there was no “moderation” of the sort you see in work calls (“mute yourself unless you’re speaking”, etc.). Each location had an entire family, so apart from talking on the call (which was chaotic with so many people anyways), people started talking among themselves. And that made it all the more chaotic.
Soon the daughter was shouting that it was getting too loud, and turned my computer volume down to the minimum (she’s figured out most of my computer controls in the last 2 months). After that, she lost interest and ran away.
A couple of weeks later, the wife was on a zoom call with a big group of her friends, and asked the daughter if she wanted to join. “I hate zoom, it’s too loud”, the daughter exclaimed and ran away.
Since then she has taken part in a couple of zoom calls, organised by her school. She sat with me once when I chatted with a (not very large) group of school friends. But I don’t think she particularly enjoys Zoom, or large video calls. And you need to remember that she is a “video call native“.
The early days of the lockdown were ripe times for people to turn into gurus, and make predictions with the hope that nobody would ever remember them in case they didn’t come through (I indulged in some of this as well). One that made the rounds was that group video calling would become much more popular and even replace group meetings (especially in the immediate aftermath of the pandemic).
I’m not so sure. While the rise of video calling has indeed given me an excuse to catch up “visually” with friends I haven’t seen in ages, I don’t see that much value from group video calls, after having participated in a few. The main problem is that there can, at a time, be only one channel of communication.
A few years back I’d written about the “anti two pizza rule” for organising parties, where I said that if you have a party, you should either have five or fewer guests, or ten or more (or something of the sort). The idea was that five or fewer can indeed have one coherent conversation without anyone being left out. Ten or more means the group naturally splits into multiple smaller groups, with each smaller group able to have conversations that add value to them.
In between (6-9 people) means it gets awkward – the group is too small to split, and too large to have one coherent conversation, and that makes for a bad party.
Now take that online. Because we have only one audio channel, there can only be one conversation for the entire group. This means that for a group of 10 or above, any “cross talk” needs to be necessarily broadcast, and that interferes with the main conversation of the group. So however large the group size of the online conversation, you can’t split the group. And the anti two pizza rule becomes “anti greater than or equal to two pizza rule”.
In other words, for an effective online conversation, you need to have four (or at max five) participants. Else you can risk the group getting unwieldy, some participants feeling left out or bored, or so much cross talk that nobody gets anything out of it.
So Zoom (or any other video chat app) is not going to replace any of our regular in-person communication media. It might to a small extent in the immediate wake of the pandemic, when people are afraid to meet large groups, but it will die out after that. OK, that is one more prediction from my side.
In related news, I swore off lecturing in Webinars some five years ago. Found it really stressful to lecture without the ability to look into the eyes of the “students”. I wonder if teachers worldwide who are being forced to lecture online because of the shut schools feel the way I do.
Those of you who know me well know that I keep taking these social media sabbaticals. Once in a while I decide that I’m spending too much time on these platforms, wasting both time and mental energy, and log off. Time has come for yet another such break.
I had a bumper day on twitter yesterday. I wrote this one tweet storm that went viral. Some 2000 plus retweets and all that. Basically I used some 15 tweets to explain Bayes’s Theorem, a concept that most people find really hard to understand.
One class of people who have become loud of twitter of late is what I call the "testing mafia". Every time someone tweets some covid-19 related news that seems mildly positive, they instinctively react "but we aren't testing enough".
For the last 24 hours, my twitter mentions have been a mess. I’ve tried various things – applying filters, switching from the native app to tweetdeck, etc. but I find that I keep checking my mentions for that dopamine rush that comes out of new followers (I have some 1500 new followers after the tweetstorm, including Chris Arnade of Dignity fame), new retweets and new likes.
And the dopamine rush is frequently killed by hate, as a tweetstorm like this will inevitably generate. I did another tweetstorm this morning detailing this hate – it has to do with the “two Overton Windows” post I’d written a couple of weeks ago.
A few days back I'd written about how the "Overton Window" has split, into what I had termed "Jamie" and "Craig" Overton windows (obviously I had to stick in a sports reference) https://t.co/PfGw0bneXy
People are so deranged that even a maths tweetstorm (like the one at the beginning of this post) can be made political, and you see people go on and on.
It is futile to engage with most people on Twitter, especially when they take their political selves too seriously. It can be exhausting, and 27 hours after I wrote that tweetstorm I’m completely exhausted.
So yeah this is not a social media sabbatical like my previous ones where I logged off all media. As things stand I’m only off Twitter (I’ve taken mitigating steps on other platforms to protect my blood pressure and serotonin).
Then again, those of you who know me well know that when I’m off twitter I’ll be writing more here. You can continue to expect that. I hope to be more productive here, and in my work (I’m swamped with work this lockdown) as well.
I continue to be available on WhatsApp, and Telegram, and email. Those of you who have my email or number can reach me in one of those places. For everything else, there’s the “contact” tab on this blog.
I must warn that this is a super long post. Also I wonder if I should put this on medium in order to get more footage.
Most models of disease spread use what is known as a “SIR” framework. This Numberphile video gives a good primer into this framework.
The problem with the framework is that it’s too simplistic. It depends primarily on one parameter “R0”, which is the average number of people that each infected patient infects. When R0 is high, each patient infects a number of other people, and the disease spreads fast. With a low R0, the disease spreads slow. It was the SIR model that was used to produce all those “flatten the curve” pictures that we were bombarded with a week or two back.
There is a second parameter as well – the recovery or removal rate. Some diseases are so lethal that they have a high removal rate (eg. Ebola), and this puts a natural limit on how much the disease can spread, since infected people die before they can infect too many people.
In any case, such modelling is great for academic studies, and post-facto analyses where R0 can be estimated. As we are currently in the middle of an epidemic, this kind of simplistic modelling can’t take us far. Nobody has a clue yet on what the R0 for covid-19 is. Nobody knows what proportion of total cases are asymptomatic. Nobody knows the mortality rate.
And things are changing well-at-a-faster-rate. Governments are imposing distancing of various forms. First offices were shut down. Then shops were shut down. Now everything is shut down, and many of us have been asked to step out “only to get necessities”. And in such dynamic and fast-changing environments, a simplistic model such as the SIR can only take us so far, and uncertainty in estimating R0 means it can be pretty much useless as well.
In this context, I thought I’ll simulate a few real-life situations, and try to model the spread of the disease in these situations. This can give us an insight into what kind of services are more dangerous than others, and how we could potentially “get back to life” after going through an initial period of lockdown.
The basic assumption I’ve made is that the longer you spend with an infected person, the greater the chance of getting infected yourself. This is not an unreasonable assumption because the spread happens through activities such as sneezing, touching, inadvertently dropping droplets of your saliva on to the other person, and so on, each of which is more likely the longer the time you spend with someone.
Some basic modelling revealed that this can be modelled as a sort of negative exponential curve that looks like this.
T is the number of hours you spend with the other person. is a parameter of transmission – the higher it is, the more likely the disease with transmit (holding the amount of time spent together constant).
The function looks like this:
We have no clue what is, but I’ll make an educated guess based on some limited data I’ve seen. I’ll take a conservative estimate and say that if an uninfected person spends 24 hours with an infected person, the former has a 50% chance of getting the disease from the latter.
This gives the value of to be 0.02888 per hour. We will now use this to model various scenarios.
Delivery
This is the simplest model I built. There is one shop, and N customers. Customers come one at a time and spend a fixed amount of time (1 or 2 or 5 minutes) at the shop, which has one shopkeeper. Initially, a proportion of the population is infected, and we assume that the shopkeeper is uninfected.
And then we model the transmission – based on our , for a two minute interaction, the probability of transmission is %.
In hindsight, I realised that this kind of a set up better describes “delivery” than a shop. With a 0.1% probability the delivery person gets infected from an infected customer during a delivery. With the same probability an infected delivery person infects a customer. The only way the disease can spread through this “shop” is for the shopkeeper / delivery person to be uninfected.
How does it play out? I simulated 10000 paths where one guy delivers to 1000 homes (maybe over the course of a week? that doesn’t matter as long as the overall infected rate in the population otherwise is constant), and spends exactly two minutes at each delivery, which is made to a single person. Let’s take a few cases, with different base cases of incidence of the disease – 0.1%, 0.2%, 0.5%, 1%, 2%, 5%, 10%, 20% and 50%.
The number of NEW people infected in each case is graphed here (we don’t care how many got the disease otherwise. We’re modelling how many got it from our “shop”). The right side graph excludes the case of zero new infections, just to show you the scale of the problem.
Notice this – even when 50% of the population is infected, as long as the shopkeeper or delivery person is not initially infected, the chances of additional infections through 2-minute delivery are MINUSCULE. A strong case for policy-makers to enable delivery of all kinds, essential or inessential.
2. SHOP
Now, let’s complicate matters a little bit. Instead of a delivery person going to each home, let’s assume a shop. Multiple people can be in the shop at the same time, and there can be more than one shopkeeper.
Let’s use the assumptions of standard queueing theory, and assume that the inter-arrival time for customers is guided by an Exponential distribution, and the time they spend in the shop is also guided by an Exponential distribution.
At the time when customers are in the shop, any infected customer (or shopkeeper) inside can infect any other customer or shopkeeper. So if you spend 2 minutes in a shop where there is 1 infected person, our calculation above tells us that you have a 0.1% chance of being infected yourself. If there are 10 infected people in the shop and you spend 2 minutes there, this is akin to spending 20 minutes with one infected person, and you have a 1% chance of getting infected.
Let’s consider two or three scenarios here. First is the “normal” case where one customer arrives every 5 minutes, and each customer spends 10 minutes in the shop (note that the shop can “serve” multiple customers simultaneously, so the queue doesn’t blow up here). Again let’s take a total of 1000 customers (assume a 24/7 open shop), and one shopkeeper.
Notice that there is significant transmission of infection here, even though we started with 5% of the population being infected. On average, another 3% of the population gets infected! Open supermarkets with usual crowd can result in significant transmission.
Does keeping the shop open with some sort of social distancing (let’s see only one-fourth as many people arrive) work? So people arrive with an average gap of 20 minutes, and still spend 10 minutes in the shop. There are still 10 shopkeepers. What does it look like when we start with 5% of the people being infected?
The graph is pretty much identical so I’m not bothering to put that here!
3. Office
This scenario simulates for N people who are working together for a certain number of hours. We assume that exactly one person is infected at the beginning of the meeting. We also assume that once a person is infected, she can start infecting others in the very next minute (with our transmission probability).
How does the infection grow in this case? This is an easier simulation than the earlier one so we can run 10000 Monte Carlo paths. Let’s say we have a “meeting” with 40 people (could just be 40 people working in a small room) which lasts 4 hours. If we start with one infected person, this is how the number of infected grows over the 4 hours.
The spread is massive! When you have a large bunch of people in a small closed space over a significant period of time, the infection spreads rapidly among them. Even if you take a 10 person meeting over an hour, one infected person at the start can result in an average of 0.3 other people being infected by the end of the meeting.
10 persons meeting over 8 hours (a small office) with one initially infected means 3.5 others (on average) being infected by the end of the day.
Offices are dangerous places for the infection to spread. Even after the lockdown is lifted, some sort of work from home regulations need to be in place until the infection has been fully brought under control.
4. Conferences
This is another form of “meeting”, except that at each point in time, people don’t engage with the whole room, but only a handful of others. These groups form at random, changing every minute, and infection can spread only within a particular group.
Let’s take a 100 person conference with 1 initially infected person. Let’s assume it lasts 8 hours. Depending upon how many people come together at a time, the spread of the infection rapidly changes, as can be seen in the graph below.
If people talk two at a time, there’s a 63% probability that the infection doesn’t spread at all. If they talk 5 at a time, this probability is cut by half. And if people congregate 10 at a time, there’s only a 11% chance that by the end of the day the infection HASN’T propagated!
One takeaway from this is that even once offices start functioning, they need to impose social distancing measures (until the virus has been completely wiped out). All large-ish meetings by video conference. A certain proportion of workers working from home by rotation.
A while back, I’d written on this blog that the phrase “war on terror” is incorrect since terrorism is not a war (actually I have written two posts on this topic. Here is the second one). A war is a staged human conflict with the aim being a political victory, and wars inevitably end in a political settlement, which in chess terms can be described as “resignation, rather than check mate”.
The issue with terrorism is that it is usually a distributed method. There is no one leader of terror. You might identify one leader and neutralise him, but that is no guarantee that the protests are going to end, since the rest of the “terrorist organisation” (a bit of an oxymoron) will keep the terror going. With a distributed organisation like a terrorist outfit, political settlements are impossible (who do you really settle with), and so the terrorism continues and there is no “victory”.
It is similar with spontaneous leaderless protests that have become the hallmark of the last decade, from Tunisia and Egypt in 2011 to Occupy Wall Street to the recent anti-CAA protests in India. To take a stark example with two protests based in Delhi, the Anna Hazare protest in 2011 was finished in fairly quick order (it started two days after India won the World Cup, and finished two days before the IPL was about to begin), while the Shaheen Bagh protests against the Citizenship Amendment Act have been going on for nearly three months now.
The difference between these two Delhi protests is that the first one (2011) had a designated leader (Anna Hazare, and maybe even Arvind Kejriwal or Kiran Bedi). And the protestors effectively followed the leader. And so when the government of the day negotiated a settlement with the leader, the protest effectively got “called off” and ended abruptly.
The Shaheen Bagh protests don’t have a designated leader to negotiate with (at least there are no obvious leaders). The government might try to negotiate with or round up or be violent to a handful of people who it thinks are the leaders, but the nature of the protest means that this is unlikely to have much effect since the rest of the “decentralised organisation” will go on.
In that sense, protests by “decentralised groups” are attritional battles where no negotiation is possible, and the only possible end is that the protestors either get bored or decide that the protest is pointless (that’s pretty much what happened with Occupy). Each member of the protesting group takes an independent decision each day (or night) whether to join the protest or not, and the protest will die down over a period of time (how long it will take depends on the size of the universe of people participating in the protest, overall interest level in the protest and how networked the protest is).
From that point of view, a leadered protest (like the Anna Hazare protest) can end suddenly (so everyone can go watch the IPL). A leaderless protest dies slowly and gradually (stronger network effects among the protestors can actually mean that the protest can die a bit faster, but still gradually).
There are claims on social media and WhatsApp groups that the communal violence in Delhi on Monday and Tuesday was designed in part to intimidate the Shaheen Bagh protestors to stop the protests. Even the violence was “successful” in achieving this objective, the leaderless nature of the protest will mean that it will only end “gradually”, more like a “halal process” rather than with a “jhatka”.
As the more perceptive of you might know, the wife runs this matrimonial advisory business. As a way of developing her business, she also accepts profiles from people looking to get married, and matches them with her clients in case she thinks there is a match.
So her aunts, aunts of aunts, aunts’ friends, aunts’ nieces’s friends, and aunt’s friends’ friends’ friends keep sending her profiles of people looking to get married. The usual means of communication for all this is WhatsApp.
The trigger for this post was this one profile she received via WhatsApp. Quickly, her marriage broking instincts decreed that this girl is going to be a good match for one of her clients. And she instantly decided to set them up. The girl’s profile was quickly forwarded (via WhatsApp) to the client boy, who quickly approved of her. All that remained to set them up was the small matter of contacting the girl and seeking her approval.
And that’s proving to be easier said than done. For while it has been established that the girl’s profile is legitimate, she has been incredibly hard to track down. The first point of contact was the aunt who had forwarded her profile. She redirected to another uncle. That uncle got contacted, and after asking a zillion questions of who the prospective boy is, and how much he earns, and what sub-sub-caste he belongs to, he directed my wife to yet another uncle. “It’s his daughter only”, the first uncle said.
So the wife contacted this yet another uncle, who interrogated more throughly, and said that the girl is not his daughter but his niece. As things stand now, he is supposed to “get back” with the girl’s contact details.
As the wife was regaling me with her sob stories of this failed match last night, I couldn’t help but observe that these matrimonial profiles that “float around” on WhatsApp are similar to “pretas”, wandering spirits of the dead (according to Hindu tradition), who wander around and haunt people around them.
The received wisdom when it comes to people who are dead is that you need to give them a decent cremation and then do the required set of rituals so that the preta gets turned into a piNDa and only visits once a year in the form of a crow. In the absence of performance of such rituals, the preta remains a preta and will return to haunt you.
The problem with floating around profiles on WhatsApp, rather than decently using a matrimonial app (such as Tinder), is that there is no “expiry” or “decent cremation”. Even once the person in question has gotten taken, there is nothing preventing the network from pulling down the profile and marking it as taken. It takes significant effort to purge the profile from the network.
Sometimes it amazes me that people can be so nonchalant about privacy and float their profiles (a sort of combination of Facebook and Twitter profiles) on WhatsApp, where you don’t know where they’ll end up. And then there is this “expiry problem”.
WhatsApp is soon going to turn us all into pretas. PiNDa only!
From the time it launched in 2005 until 2012 or so when it was folded into Hangouts, I pretty much lived my life on Google Talk. The standard operating procedure when I came home from work (back then, I used to have jobs) was to open up my computer, open Google Talk and then ping 5-6 people who were online then.
The beauty of Google Talk was that you know who exactly was online at what point in time. So when you sprayed around your “hey how are you”s, you could target them at people who you knew were (or at least appeared to be) available to chat. This meant this had a high hit rate, and you could have productive conversations.
The problem with other chat mechanisms such as WhatsApp is that there is no “online” and “offline” mode. For example, if i’m working and I’m getting stuck and could use a quick conversation, turning my status to “available” on a chat room can then be a magnet for people to ping me. Or I can see which of my friends is online using their statuses, and then ping them.
With WhatsApp, I need to guess who might be available for conversation at this point in time. And that means lots of messages sent out which get responded to at the most inopportune of times (when I’ve got back my flow of work thought, for example).
In yesterday’s business standard I read about this app (whose name I now forget about ) which is trying to restart this kind of chats, signalling “availability” and chat rooms. Hopefully something like that will take off!
Instagram is really good at what I call “one dimensional psychographic targeting”.
Essentially, based on the photos and videos (more likely hashtags) that you see, spend time on, like and comment, the platform figures out some of your interests and targets at you advertisements of products that serve these interests. And instagram manages to combine this with demographic information (where you live, etc.) to target advertisements better at you.
For example, of late I’ve been looking at a lot of weightlifting stuff on Instagram – I follow most of the coaches at my gym, and a few other handles that post fitness stuff. I’ve even posted a video of myself deadlifting.
As a result, Instagram has been following me with advertisements related to fitness, and the combination with demographics means I’m being served stuff I can get in Bangalore. For example, last two days I’ve been seeing ads of my own gym (!!). There are ads for whey proteins and healthy foods of all kinds as well.
This targeting is not perfect – for the last few months, ever since I returned to India, I’ve been bombarded on Instagram with advertisements asking me to emigrate to Canada (I don’t know what makes it think I want to move abroad again given I’ve just moved back home). The seemingly un-targeted mattress advertisements are everywhere. The shirt advertisements as well (though recently I uploaded a picture of my wardrobe on Instagram).
Nevertheless, this is a massive step up from what marketers were able to do a generation ago, where they could at best target based on a demographic. Marketers might have created elaborate psychographic or behavioural profiles of their target audiences, but when it came to advertising, the media available (newspaper, television and outdoors) meant that they had to collapse it into a demographic profile.
Instagram is not perfect, though. To the best of my knowledge, it can only target me on one “psychographic dimension” (“interested in weight lifting”, “interested in coloured chinos”, “likes Bangalore”) along with a multitude of demographic dimensions (I’m sure it’s figured out my gender, age group and maybe even caste, even if it exists in some vector somewhere and no human knows these classifications).
However, when you have created elaborate psychographic profiles, collapsing them into one dimension is still a simplification process. And so you get a reasonable degree of error in targeting. So I’m wondering what can be done that can enable advertisers to target me with more specific products that I might be interested in.
Finally, really how much are the likes of Charles Tyrwhitt, and some mattress brand whose name I don’t recall, willing to pay for their campaigns, given that their untargeted campaigns have beaten the highly targeted campaigns of the fitness guys and coffee companies to reach my eyeballs?




 is a parameter of transmission – the higher it is, the more likely the disease with transmit (holding the amount of time spent together constant).
is a parameter of transmission – the higher it is, the more likely the disease with transmit (holding the amount of time spent together constant).
 of the population is infected, and we assume that the shopkeeper is uninfected.
of the population is infected, and we assume that the shopkeeper is uninfected.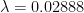 , for a two minute interaction, the probability of transmission is
, for a two minute interaction, the probability of transmission is 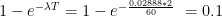 %.
%.



{kind=link}