Most finance textbooks, at least the ones that are popular in Business Schools, use standard deviation as a measure of volatility of a stock price. In this post, we will examine why it is not a great idea. To put it in one line, the use of standard deviation loses information on the ordering of the price movement.
As earlier, let us look at two data sets and try to measure their volatility. Let us consider two time series (let’s simply call them “series1” and “series2”) and try and compare their volatilities. The table here shows the two series:
 What can you say of the two series now? You think they are similar? You might notice that both contain the same set of numbers, but jumbled up. Let us look at the volatility as expressed by standard deviation. Unsurprisingly, since both series contain the same set of numbers, the volatility of both series is identical – at 8.655.
What can you say of the two series now? You think they are similar? You might notice that both contain the same set of numbers, but jumbled up. Let us look at the volatility as expressed by standard deviation. Unsurprisingly, since both series contain the same set of numbers, the volatility of both series is identical – at 8.655.
However, does this mean that the two series are equally volatile? Not particularly, as you can see from this graph of the two series:

It is clear from the graph (if it was not clear from the table already) that Series 2 is much more volatile than series 1. So how can we measure it? Most textbooks on quantitative finance (as opposed to textbooks on finance) use “Quadratic Variation” as a measure of volatility. How do we measure quadratic variation?
If we have a series of numbers from 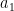 to
to 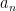 , then the quadratic variation of this series is measured as
, then the quadratic variation of this series is measured as
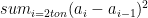
Notice that the primary difference feature of the quadratic variation is that it takes into account the sequence. So when you have something like series 2, with alternating positive and negative jumps, it gets captured in the quadratic variation. So what would be the quadratic variation values for the two time series we have here?
The QV of series 1 is 29 while that of series 2 is a whopping 6119, which is probably a fair indicator of their relative volatilities.
So why standard deviation?
Now you might ask why textbooks use standard deviation at all then, if it misses out so much of the variation. The answer, not surprisingly, lies in quantitative finance. When the price of a stock (X) is governed by a Wiener process, or
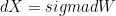
then the quadratic variation of the stock price (between time 0 and time t) can be shown to be 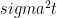 , which for t = 1 is
, which for t = 1 is 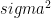 which is the variance of the process.
which is the variance of the process.
Because for a particular kind of process, which is commonly used to model stock price movement, the quadratic variation is equal to variance, variance is commonly used as a substitute for quadratic variation as a measure of volatility.
However, considering that in practice stock prices are seldom Brownian (either arithmetic or geometric), this equivalence doesn’t necessarily hold.
This is also a point that Benoit Mandelbrot makes in his excellent book The (mis)Behaviour of Markets. He calls this the Joseph effect (he uses the biblical story of Joseph, who dreamt of seven fat cows being eaten by seven lean foxes, and predicted that seven years of Nile floods would be followed by seven years of drought). Financial analysts, by using a simple variance (or standard deviation) to characterize volatility, miss out on such serial effects.