I’m currently reading a book called How the World Thinks: A global history of philosophy by Julian Baggini. I must admit I bought this by mistake – I was at a bookshop where I saw this book and went to the Amazon website to check reviews. And by mistake I ended up hitting buy. And before I got around to returning it, I started reading and liking it, so I decided to keep it.
In any case, this book is a nice comparative history of world philosophies, with considerable focus on Indian, Chinese, Japanese and Islamic philosophies. The author himself is trained in European/Western philosophy, but he keeps an open mind and so far it’s been an engaging read.
Rather than approaching the topic in chronological order, like some historians might have been tempted to do, this book approaches it by concept, comparing how different philosophies treat the same concept. And the description of Indian philosophy in the “Logic” chapter caught my eye, in the sense that it reminded me of Bayesian logic, and a piece I’d written a few years back.
Talking about Hindu philosophy and logic, Baggins writes:
For instance, the Veda affirms that when the appropriate sacrifice for the sake of a son is performed, a son will be produced. But it is often observed that a son is not produced, even though the sacrifice has been performed. This would seem to be pretty conclusive proof that the sacrifices don’t work and so the Veda is flawed. Not, however, if you start from the assumption that the Veda cannot be flawed.
In other words, Hindu Philosophy starts with the Bayesian prior that the Veda cannot be flawed. Consequently, irrespective of how strong the empirical evidence that the Vedas are flawed, the belief in the Vedas can never change! On the other hand, if the prior probability that the Vedas were flawed were positive but even infinitesimal, then the amount of evidences such as the above (where sacrifices that are supposed to have produced sons but fail to do so) would over time result in the probability of the Vedas being flawed increasing, and soon tending to 1.
In 2015, I had written in Mint about how Bayesian logic can be used to explain online flame wars. There again, I had written about how when people start with extreme opinions (probabilities equal to 0 or 1), even the strongest contrary evidence is futile to get them to change their opinions. And hence in online flame wars you have people simply talking past each other because neither is willing to update their opinions in the face of evidence.
Coming back to Hindu philosophy, this prior belief that the Vedas cannot be flawed reminds me of the numerous futile arguments with some of my relatives who are of a rather religious persuasion. In each case I presented to them what seemed like strong proof that some of their assumptions of religion are flawed. In each case, irrespective of the strength of my evidence, they refused to heed my argument. Now, looking at the prior of a religious Hindu – that the likelihood of the Vedas being flawed is 0 (not infinitesimal, but 0), it is clear why my arguments fell on deaf ears.
In any case, Baggini goes on to say:
By this logic, if ‘a son is sure to be produced as a result of performing the sacrifice’ but a son is not produced, it can only follow that the sacrifice was not performed correctly, however much it seems that it was performed properly. By such argument, the Ny?ya S?tra can safely conclude, ‘Therefore there is no untruth in the Veda.’


 , the average returns or the drift, is defined as “returns per unit time”. So a stock that returns, on average, 10% in a year returns 20% in two years. So returns has dimensions
, the average returns or the drift, is defined as “returns per unit time”. So a stock that returns, on average, 10% in a year returns 20% in two years. So returns has dimensions 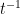 , and multiplying it with
, and multiplying it with 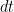 which has the unit of time renders it dimensionless.
which has the unit of time renders it dimensionless.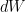 is the Wiener Process, and is defined such that
is the Wiener Process, and is defined such that 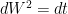 . This implies that
. This implies that 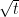 . This means that the equation is meaningful if and only if
. This means that the equation is meaningful if and only if  has dimensions
has dimensions 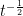 , which is the same as saying that
, which is the same as saying that 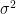 has dimensions
has dimensions  , which is the same as the dimensions of the mean returns.
, which is the same as the dimensions of the mean returns.

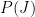 , which makes the probability of him/her being “nice” at
, which makes the probability of him/her being “nice” at 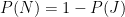 . Now when he/she does or says something (let’s call this event
. Now when he/she does or says something (let’s call this event  ), you implicitly do a Bayesian updation of these probabilities.
), you implicitly do a Bayesian updation of these probabilities. (the standard Bayesian formula).
(the standard Bayesian formula).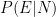 and
and 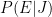 in it.
in it. is just one minus the above quantity (we assume that there is nothing else that can cause L(t)) .
is just one minus the above quantity (we assume that there is nothing else that can cause L(t)) .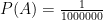
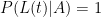
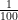 . Now,
. Now, 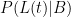 is tricky, and the reason the (t) qualifier has been added to L. The larger t is, the smaller the value of L(t)|B. If there is a bus schedule breakdown, there is probably a 50% probability that I’m not home an hour after “usual”. But there is only a 10% probability that I’m not home two hours after “usual” because a bus breakdown happened. So
is tricky, and the reason the (t) qualifier has been added to L. The larger t is, the smaller the value of L(t)|B. If there is a bus schedule breakdown, there is probably a 50% probability that I’m not home an hour after “usual”. But there is only a 10% probability that I’m not home two hours after “usual” because a bus breakdown happened. So
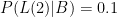


 . In other words, if I didn’t get home an hour later than usual, the odds that I had been knocked down or kidnapped was just one in five thousand!
. In other words, if I didn’t get home an hour later than usual, the odds that I had been knocked down or kidnapped was just one in five thousand!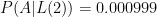 or one in a thousand! So notice that the later I am, the higher the odds that I’m in trouble. Yet, the numbers (admittedly based on the handwaving assumptions above) are small enough for us to not worry!
or one in a thousand! So notice that the later I am, the higher the odds that I’m in trouble. Yet, the numbers (admittedly based on the handwaving assumptions above) are small enough for us to not worry!