So the Football World Cup season is upon us, and this means that investment banking analysts are again engaging in the pointless exercise of trying to predict who will win the World Cup. And the funny thing this time is that thanks to MiFiD 2 regulations, which prevent banking analysts from giving out reports for free, these reports aren’t in the public domain.
That means we’ve to rely on media reports of these reports, or on people tweeting insights from them. For example, the New York Times has summarised the banks’ predictions on the winner. And this scatter plot from Goldman Sachs will go straight into my next presentation on spurious correlations:
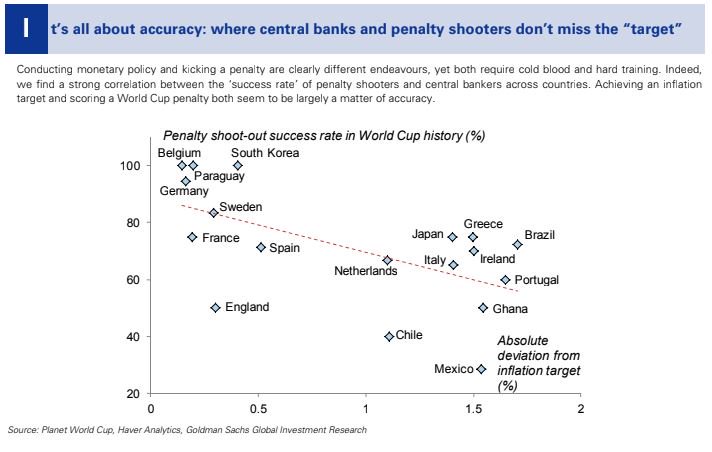
Different banks have taken different approaches to predict who will win the tournament. UBS has still gone for a classic Monte Carlo simulation approach, but Goldman Sachs has gone one ahead and used “four different methods in artificial intelligence” to predict (for the third consecutive time) that Brazil will win the tournament.
In fact, Goldman also uses a Monte Carlo simulation, as Business Insider reports.
The firm used machine learning to run 200,000 models, mining data on team and individual player attributes, to help forecast specific match scores. Goldman then simulated 1 million possible variations of the tournament in order to calculate the probability of advancement for each squad.
But an insider in Goldman with access to the report tells me that they don’t use the phrase itself in the report. Maybe it’s a suggestion that “data scientists” have taken over the investment research division at the expense of quants.
I’m also surprised with the reporting on Goldman’s predictions. Everyone simply reports that “Goldman predicts that Brazil will win”, but surely (based on the model they’ve used), that prediction has been made with a certain probability? A better way of reporting would’ve been to say “Goldman predicts Brazil most likely to win, with X% probability” (and the bank’s bets desk in the UK could have placed some money on it).

ING went rather simple with their forecasts – simply took players’ transfer values, and summed them up by teams, and concluded that Spain is most likely to win because their squad is the “most valued”. Now, I have two major questions about this approach – firstly, it ignores the “correlation term” (remember the famous England conundrum of the noughties of fitting Gerrard and Lampard into the same eleven?), and assumes a set of strong players is a strong team. Secondly, have they accounted for inflation? And if so, how have they accounted for inflation? Player valuation (about which I have a chapter in my book) has simply gone through the roof in the last year, with Mo Salah at £35 million being considered a “bargain buy”.
Nomura also seems to have taken a similar approach, though they have in some ways accounted for the correlation term by including “team momentum” as a factor!
Anyway, I look forward to the football! That it is live on BBC and ITV means I get to watch the tournament from the comfort of my home (a luxury in England!). Also being in England means all matches are at a sane time, so I can watch more of this World Cup than the last one.


