Tagging offers an efficient method to both searching and for identifying customer preferences on the axis most appropriate for the customer
The traditional way to organise a retail catalogue is by means of hierarchical categorisation. If you’re selling clothes, for example, you first divide it into men’s and women’s, then into formal and casual, and then into different items of clothing and so on. With a good categorisation, each SKU will have a unique “path” down the category tree. For traditional management purposes, this kind of categorisation might be useful, but it doesn’t lend itself well to both searching and pattern recognition.
To take a personal example (note that I’m going into anecdata territory here), I’m in the market for a hooded sweatshirt, and it has been extremely hard to find. Having given up on a number of “traditional retail” stores in the “High Street” (11th Main Road, 4th Block, Jayanagar, Bangalore) close to where I stay, I decided to check online sources and they’ve left me disappointed, too.
To be more precise, I’m looking for a grey sweatshirt made with a mix of cotton and wool (“traditional sweatshirt material”) with a zipper down the front, pockets large enough to keep my hands and a hood. Of size 42. This description is as specific as it gets and I don’t imagine any brand having more than a small number of SKUs that fit this specification.
In case I were shopping offline in a well-stocked store (perhaps a “well stocked offline store” is entering mythical territory nowadays), I would repeat the above paragraph to a store attendant (good store attendants are also very hard to find nowadays) and he/she would pick out the sweatshirts that would conform to these specifications and I would buy one of them. The question is how one can replicate this experience in online shopping.
In other words, how can we set up our online customer catalog such that it becomes easy for shoppers to search specifically for what they’re looking for. Currently, most online stores follow a “categorisation” format, where you step into two or three levels of categorisation, where you’re shown a large assortment. This, however, doesn’t allow for efficient search. Let me illustrate by my own experience this morning.
1. Amazon.in : I hit “hoodies” in the search bar, and got shown a large assortment of hoodies. I can drill deeper in terms of sleeve length, material, colour and brand. My choice of material (which I’m particular about) is not there in the given list. There are too many colour choices and I can’t simply say “grey” and be shown all greys. There is no option to say i want a zip-open front, or a cotton-wool mix. My search ends there.
2. Jabong (rumoured to be bought by Amazon shortly): I hover over “Men’s”, click on “winter wear” and then on “hoodies”. There is a large assortment of both material (cotton-wool mix not here) and brand. There are several colours available, but no way for me to tell the system I’m looking for a zip-down hoodie. I can set my price-range and size, though. Search ends at a point when there’s too much choice.
3. Flipkart: Hover over “men’s”, click “winter wear” and then sweatshirt. Price, size and brand are the only axes on which I can drill down further. The least impressive of all the sites I’ve seen. Too much choice again at a point when I end search.
4. Myntra (recently bought by Flipkart, but not yet merged): The most impressive of all sites. I hover over “Men’s” and click on sweaters and sweatshirts (one less click than Jabong or Flipkart). After I click on “sweatshirts” it gives me a “closure” option (this is the part that impresses me) where I can say I want a zippered front. No option to indicate hood or material, though.
In each of the above, it seems like the catalog has been thought up in a hierarchical format, with little attention paid to tagging. There might be some tags attached such as “brand” but these are tags that are available to every item. The key to tagging is that not all tags need to be applicable for all items. For example, “closure” (zippered or buttoned or open) is applicable only to sweatshirts. Sleeve length is applicable only to tops.
In addition to search (as illustrated above), the purpose of tagging is to identify patterns in purchases and know more about customers. The basic idea is that people’s preferences could be along several axes, and at the time of segmentation and bucketing you are not sure which axis describes the person’s preferences best. So by having a large number of tags that you assign to each SKU (this sadly is a highly manual process), you give yourself a much superior chance of getting to know the customer.
In terms of technological capability, things have advanced much in terms of getting to know the customer. For example, it is now really quick to do a Market Basket Analysis based on large numbers of bills, which helps you identify patterns in purchase. With the technology bit being easy, the key to learning more about your customers is the framework you employ to “encase” the technology. And without efficient tagging, you are giving yourself a lesser chance of categorising the customer on the right axis.
Of course for someone used to relational databases, tagging requires non-trivial methods of storage. Firstly the number of tags varies widely by item. Secondly, tags can themselves have a hierarchy, and items might not necessarily be associated with the lowest level of tag. Thirdly, tagging is useless without efficient searching, at various levels, and it is a non-trivial technological problem to solve. But while the problems are non-trivial, the solutions are well-known and advantages large enough that whether to use tags or not is a no-brainer for an organisation that wants to use data in its decision-making.

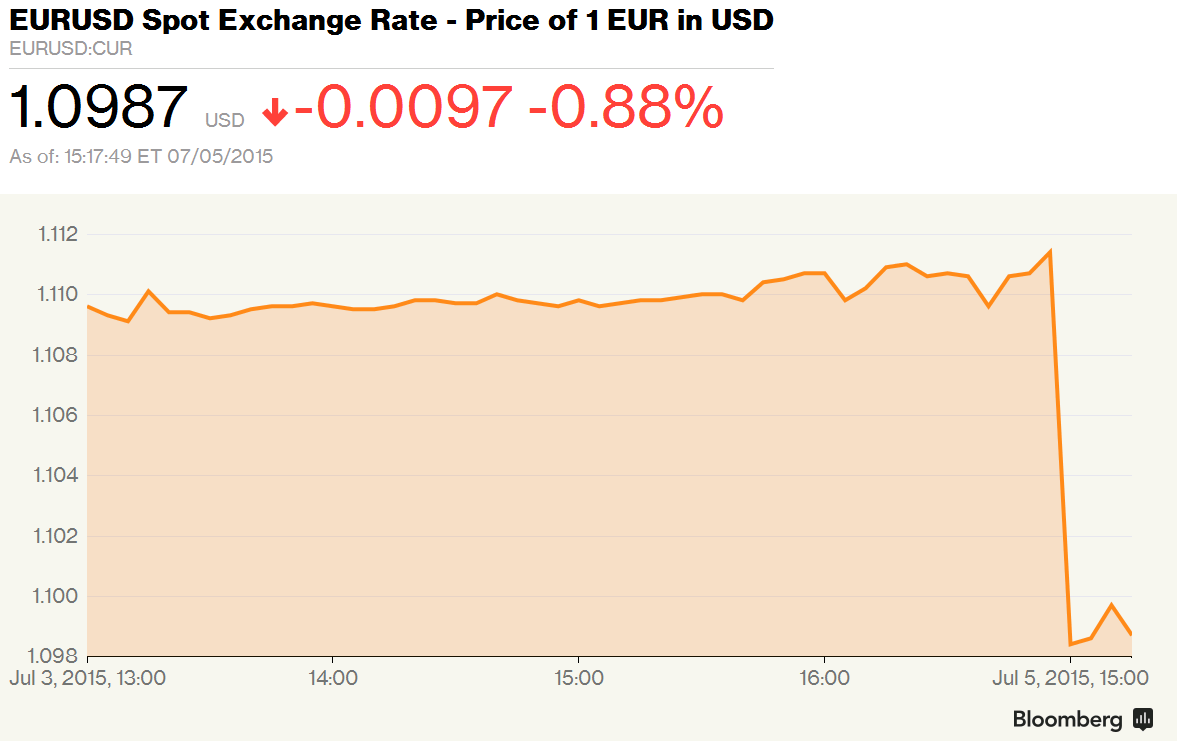 You notice the spectacular drop right? Cliff-like. You think the Euro is doomed now that the Greeks have voted “no”? Do not despair, for all you need to do is to look at the axis, and the axis labels.
You notice the spectacular drop right? Cliff-like. You think the Euro is doomed now that the Greeks have voted “no”? Do not despair, for all you need to do is to look at the axis, and the axis labels.
