There was a point in time when the use of artificial intelligence or machine learning or any other kind of intelligence in a product was a source of competitive advantage and differentiation. Nowadays, however, many people have got so spoiled by the use of intelligence in many products they use that it has become more of a hygiene factor.
Take this morning’s post, for example. One way to look at it is that Spotify with its customisation algorithms and recommendations has spoiled me so much that I find Amazon’s pushing of Indian music irritating (Amazon’s approach can be called as “naive customisation”, where they push Indian music to me only because I’m based in India, and not learn further based on my preferences).
Had I not been exposed to the more intelligent customisation that Spotify offers, I might have found Amazon’s naive customisation interesting. However, Spotify’s degree of customisation has spoilt me so much that Amazon is simply inadequate.
This expectation of intelligence goes beyond product and service classes. When we get used to Spotify recommending music we like based on our preferences, we hold Netflix’s recommendation algorithm to a higher standard. We question why the Flipkart homepage is not customised to us based on our previous shopping. Or why Google Maps doesn’t learn that some of us don’t like driving through small roads when we can help it.
That customers take intelligence for granted nowadays means that businesses have to invest more in offering this intelligence. Easy-to-use data analysis and machine learning packages mean that at least some part of an industry uses intelligence in at least some form (even if they might do it badly in case they fail to throw human intelligence into the mix!).
So if you are in the business of selling to end customers, keep in mind that they are used to seeing intelligence everywhere around them, and whether they state it or not, they expect it from you.

 , the area of the polygon thus formed equals
, the area of the polygon thus formed equals  . It is not hard to see that for any value of
. It is not hard to see that for any value of 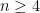 , the ordering of the “axes” makes a material difference in the area of the chart.
, the ordering of the “axes” makes a material difference in the area of the chart.






