At the outset I must say that I’m deeply disappointed (based on the sources I’ve seen, mostly based on googling) with the reporting around the US presidential elections.
For example, if I google, I get something like “Biden leads Trump 225-213”. At the outset, that seems like useful information. However, the “massive discretisation” of the US electorate means that it actually isn’t. Let me explain.
Unlike India, where each of the 543 constituencies have a separate election, and the result of one doesn’t influence another, the US presidential election is at the state level. In all but a couple of small states, the party that gets most votes in the state gets all the votes of that state. So something like California is worth 55 votes. Florida is worth 29 votes. And so on.
And some of these states are “highly red/blue” states, which means that they are extremely likely to vote for one of the two parties. For example, a victory is guaranteed for the Democrats in California and New York, states they had won comprehensively in the 2016 election (their dominance is so massive in these states that once a friend who used to live in New York had told me that he “doesn’t know any Republican voters”).
Just stating Biden 225 – Trump 213 obscures all this information. For example, if Biden’s 225 excludes California, the election is as good as over since he is certain to win the state’s 55 seats.
Also – this is related to my rant last week about the reporting of the opinion polls in the US – the front page on Google for US election results shows the number of votes that each candidate has received so far (among votes that have been counted). Once again, this is highly misleading, since the number of votes DOESN’T MATTER – what matters is the number of delegates (“seats” in an Indian context) each candidate gets, and that gets decided at the state level.
Maybe I’ve been massively spoilt by Indian electoral reporting, pioneered by the likes of NDTV. Here, it’s common to show the results and leads along with margins. It is common to show what the swing is relative to the previous elections. And some publications even do “live forecasting” of the total number of seats won by each party using a variation of the votes to seats model that I’ve written about.
American reporting lacks all of this. Headline numbers are talked about. “Live reports” on sites such as Five Thirty Eight are flooded with reports of individual senate seats, which to me sitting halfway round the world, is noise. All I care about is the likelihood of Trump getting re-elected.
Reports talk about “swing states” and how each party has performed in these, but neglect mentioning which party had won it the last time. So “Biden leading in Arizona” is of no importance to me unless I know how Arizona had voted in 2016, and what the extent of the swing is.
So what would I have liked? 225-213 is fine, but can the publications project it to the full 538 seats? There are several “models” they can use for this. The simplest one is to assume that states that haven’t declared leads yet have voted the same way as they did in 2016. One level of complexity can be using the votes to seats model, by estimating swings from the states that have declared leads, and then applying it to similar states that haven’t given out any information. And then you can get more complicated, but you realise it isn’t THAT complicated.
All in all, I’m disappointed with the reporting. I wonder if the split of American media down political lines has something to do with this.
(Relative) old-time readers of this blog might recall that in 2013-14 I wrote a column called “Election Metrics” for Mint, where I used data to analyse elections and everything else related to that. This being the election where Narendra Modi suddenly emerged as a spectacular winner, the hype was high. And I think a lot of people did read my writing during that time.
In any case, somewhere during that time, my editor called me “Nate Silver of India”.
I always suspected @karthiks is India's Nate Silver. His piece in today's Mint seals the argument for me. http://t.co/4RxxA4Qo9d
I followed that up with an article on why “there can be no Nate Silver in India” (now they seem to have put it behind a sort of limited paywall). In that, I wrote about the polling systems in India and in the US, and about how India is so behind the US when it comes to opinion polling.
Basically, India has fewer opinion polls. Many more political parties. A far more diverse electorate. Less disclosure when it comes to opinion polls. A parliamentary system. And so on and so forth.
Now, seven years later, as we are close to a US presidential election, I’m not sure the American opinion polls are as great as I made them out to be. Sure, all the above still apply. And when these poll results are put in the hands of a skilled analyst like Nate Silver, it is possible to make high quality forecasts based on that.
However, the reporting of these polls in the mainstream media, based on my limited sampling, is possibly not of much higher quality than what we see in India.
Basically I don’t understand why analysts abroad make such a big deal of “vote share” when what really matters is the “seat share”.
Like in 2016, Hillary Clinton won more votes than Donald Trump, but Trump won the election because he got “more seats” (if you think about it, the US presidential elections is like a first past the post parliamentary election with MASSIVE constituencies (California giving you 55 seats, etc.) ).
And by looking at the news (and social media), it seems like a lot of Americans just didn’t seem to get it. People alleged that Trump “stole the election” (while all he did was optimise based on the rules of the game). They started questioning the rules. They seemingly forgot the rules themselves in the process.
I think this has to do with the way opinion polls are reported in the US. Check out this graphic, for example, versions of which have been floating around on mainstream and social media for a few months now.
This shows voting intention. It shows what proportion of people surveyed have said they will vote for one of the two candidates (this is across polls. The reason this graph looks so “continuous” is that there are so many polls in the US). However, this shows vote share, and that might have nothing to do with seat share.
The problem with a lot (or most) opinion polls in India is that they give seat share predictions without bothering to mention what the vote share prediction is. Most don’t talk about sample sizes. This makes it incredibly hard to trust these polls.
The US polls (and media reports of those) have the opposite problem – they try to forecast vote share without trying to forecast how many “seats” they will translate to. “Biden has an 8 percentage point lead over Trump” says nothing. What I’m looking for is something like “as things stand, Biden is likely to get 20 (+/- 15) more electoral college votes than Trump”. Because electoral college votes is what this election is about. The vote share (or “popular vote”, as they call it in the US (perhaps giving it a bit more legitimacy than it deserves) ), for the purpose of the ultimate result, doesn’t matter.
In the Indian context, I had written this piece on how to convert votes to seats (again paywalled, it seems like). There, I had put some pictures (based on state-wise data from general elections in India before 2014).
An image from my article for Mint in 2014 on converting votes to seats. Look at the bottom left graph
What I had found is that in a two-cornered contest, small differences in vote share could make a massive difference in the number of seats won. This is precisely the situation that they have in the US – a two cornered contest. And that means opinion polls predicting vote shares only should be taken with some salt.
Through a combination of luck and competence, my home state of Karnataka has handled the Covid-19 crisis rather well. While the total number of cases detected in the state edged past 2000 recently, the number of locally transmitted cases detected each day has hovered in the 20-25 range.
It might make news that Karnataka has crossed 2000 covid-19 cases (cumulatively).
However, the state has only 20-25 locally transmitted cases per day (increasing at a very slow rate)
Perhaps the low case volume means that Karnataka is able to give out data at a level that few others states in India are providing. For each case, the rationale behind why the patient was tested (which is usually the source where they caught the disease) is given. This data comes out in two daily updates through the @dhfwka twitter handle.
There was this research that came out recently that showed that the spread of covid-19 follows a classic power law, with a low value of “alpha”. Basically, most infected people don’t infect anyone else. But there are a handful of infected people who infect lots of others.
The Karnataka data, put out by @dhfwka and meticulously collected and organised by the folks at covid19india.org (they frequently drive me mad by suddenly changing the API or moving data into a new file, but overall they’ve been doing stellar work), has sufficient information to see if this sort of power law holds.
For every patient who was tested thanks to being a contact of an already infected patient, the “notes” field of the data contains the latter patient’s ID. This way, we are able to build a sort of graph on who got the disease from whom (some people got the disease “from a containment zone”, or out of state, and they are all ignored in this analysis).
From this graph, we can approximate how many people each infected person transmitted the infection to. Here are the “top” people in Karnataka who transmitted the disease to most people.
Patient 653, a 34 year-old male from Karnataka, who got infected from patient 420, passed on the disease to 45 others. Patient 419 passed it on to 34 others. And so on.
Overall in Karnataka, based on the data from covid19india.org as of tonight, there have been 732 cases where a the source (person) of infection has been clearly identified. These 732 cases have been transmitted by 205 people. Just two of the 205 (less than 1%) are responsible for 79 people (11% of all cases where transmitter has been identified) getting infected.
The top 10 “spreaders” in Karnataka are responsible for infecting 260 people, or 36% of all cases where transmission is known. The top 20 spreaders in the state (10% of all spreaders) are responsible for 48% of all cases. The top 41 spreaders (20% of all spreaders) are responsible for 61% of all transmitted cases.
Now you might think this is not as steep as the “well-known” Pareto distribution (80-20 distribution), except that here we are only considering 20% of all “spreaders”. Our analysis ignores the 1000 odd people who were found to have the disease at least one week ago, and none of whose contacts have been found to have the disease.
I admit this graph is a little difficult to understand, but basically I’ve ordered people found for covid-19 in Karnataka by number of people they’ve passed on the infection to, and graphed how many people cumulatively they’ve infected. It is a very clear pareto curve.
The exact exponent of the power law depends on what you take as the denominator (number of people who could have infected others, having themselves been infected), but the shape of the curve is not in question.
Essentially the Karnataka validates some research that’s recently come out – most of the disease spread stems from a handful of super spreaders. A very large proportion of people who are infected don’t pass it on to any of their contacts.
If you think you’re a data visualisation junkie, it’s likely that you’ve read Edward Tufte’s Visual Display Of Quantitative Information. If you are only a casual observer of the topic, you are likely to have come across these gifs that show you how to clean up a bar graph and a data table.
And if you are a real geek when it comes to visualisation, and you are the sort of person who likes long-form articles about the information technology industry, I’m sure you’ve come across Eugene Wei’s massive essay on “remove the legend to become one“.
The idea in the last one is that when you have something like a line graph, a legend telling you which line represents what can be distracting, especially if you have too many lines. You need to constantly move your head back and forth between the chart and the table as you try to interpret it. So, Wei says, in order to “become a legend” (by presenting information that is easily consumable), you need to remove the legend.
My equivalent of that for bar graphs is to put data labels directly on the bar, rather than having the reader keep looking at a scale (the above gif with bar graphs also does this). It makes for easier reading, and by definition, the bar graph conveys the information on the relative sizes of the different data points as well.
There is one problem, though, especially when you’re drawing what my daughter calls “sleeping bar graphs” (horizontal) – where do you really put the text so that it is easily visible? This becomes especially important if you’re using a package like R ggplot where you have control over where to place the text, what size to use and so on.
The basic question is – do you place the label inside or outside the bar? I was grappling with this question yesterday while making some client chart. When I placed the labels inside the bar, I found that some of the labels couldn’t be displayed in full when the bars were too short. And since these were bars that were being generated programmatically, I had no clue beforehand how long the bars would be.
So I decided to put all the labels outside. This presented a different problem – with the long bars. The graph would automatically get cut off a little after the longest bar ended, so if you placed the text outside, then the labels on the longest bar couldn’t be seen! Again the graphs have to come out programmatically so when you’re making them you don’t know what the length of the longest bar will be.
I finally settled on this middle ground – if the bar is at least half as long as the longest bar in the chart set, then you put the label inside the bar. If the bar is shorter than half the longest bar, then you put the label outside the bar. And then, the text inside the bar is right-justified (so it ends just inside the end of the bar), and the text outside the bar is left-justified (so it starts exactly where the bar ends). And ggplot gives you enough flexibility to decide the justification (‘hjust’) and colour of the text (I keep it white if it is inside the bar, black if outside), that the whole thing can be done programmatically, while producing nice and easy-to-understand bar graphs with nice labels.
Obviously I can’t share my client charts here, but here is one I made for the doubling days for covid-19 cases by district in India. I mean it’s not exactly what I said here, but comes close (the manual element here is a bit more).
In fact, there is wide divergence within states as well Within states, we see high divergence in doubling rates across districts pic.twitter.com/jIU9CmitRx
I seem to be becoming a sort of “testing expert”, though the so-called “testing mafia” (ok I only called them that) may disagree. Nothing external happened since the last time I wrote about this topic, but here is more “expertise” from my end.
As some of you might be aware, I’ve now created a script that does the daily updates that I’ve been doing on Twitter for the last few weeks. After I went off twitter last week, I tried for a couple of days to get friends to tweet my graphs. That wasn’t efficient. And I’m not yet over the twitter addiction enough to log in to twitter every day to post my daily updates.
So I’ve done what anyone who has a degree in computer science, and who has a reasonable degree of self-respect, should do – I now have this script (that runs on my server) that generates the graph and some mildly “intelligent” commentary and puts it out at 8am everyday. Today’s update looked like this:
This will go out as an automated update henceforth. Overall, cases in India are now doubling every 9.6 days pic.twitter.com/Qkd0t1u83k
Sometimes I make the mistake of going to twitter and looking at the replies to these automated tweets (that can be done without logging in). Most replies seem to be from the testing mafia. “All this is fine but we’re not testing enough so can’t trust the data”, they say. And then someone goes off on “tests per million” as if that is some gold standard.
As I discussed in my last post on this topic, random testing is NOT a good thing here. There are several ethical issues with that. The error rates with the testing means that there is a high chance of false positives, and also false negatives. So random testing can both “unleash” infected people, and unnecessarily clog hospital capacity with uninfected.
So if random testing is not a good metric on how adequately we are testing, what is? One idea comes from this Yahoo report on covid management in Vietnam.
According to data published by Vietnam’s health ministry on Wednesday, Vietnam has carried out 180,067 tests and detected just 268 cases, 83% of whom it says have recovered. There have been no reported deaths.
The figures are equivalent to nearly 672 tests for every one detected case, according to the Our World in Data website. The next highest, Taiwan, has conducted 132.1 tests for every case, the data showed
Total tests per positive case. Now, that’s an interesting metric. The basic idea is that if most of the people we are testing show positive, then we simply aren’t testing enough. However, if we are testing a lot of people for every positive case, then it means that we are also testing a large number of marginal cases (there is one caveat I’ll come to).
Also, tests per positive case also takes the “base rate” into effect. If a region has been affected massively, then the base rate itself will be high, and the region needs to test more. A less affected region needs less testing (remember we only test those with a high base rate). And it is likely that in a region with a higher base rate, more positive cases are found (this is a deadly disease. So anyone with more than a mild occurrence of the disease is bound to get themselves tested).
The only caveat here is that the tests need to be “of high quality”, i.e. they should be done on people with high base rates of having the disease. Any measure that becomes a metric is bound to be gamed, so if tests per positive case becomes a metric, it is easy for a region to game that by testing random people (rather than those with high base rates). For now, let’s assume that nobody has made this a “measure” yet, so there isn’t that much gaming yet.
So how is India faring? Based on data from covid19india.org, until yesterday India had done (as of yesterday, 23rd April) about 520,000 tests, of which about 23,000 people have tested positive. In other words, India has tested 23 people for every positive test. Compared to Vietnam (or even Taiwan) that’s a really low number.
However, different states are testing to different extents by this metric. Again using data from covid19india.org, I created this chart that shows the cumulative “tests per positive case” in each state in India. I drew each state in a separate graph, with different scales, because they were simply not comparable.
Notice that Maharashtra, our worst affected state is only testing 14 people for every positive case, and this number is going down over time. Testing capacity in that state (which has, on an absolute number, done the maximum number of tests) is sorely stretched, and it is imperative that testing be scaled up massively there. It seems highly likely that testing has been backlogged there with not enough capacity to test the high base rate cases. Gujarat and Delhi, other badly affected states, are also in similar boats, testing only 16 and 13 people (respectively) for every infected person.
At the other end, Orissa is doing well, testing 230 people for every positive case (this number is rising). Karnataka is not bad either, with about 70 tests per case (again increasing. The state massively stepped up on testing last Thursday). Andhra Pradesh is doing nearly 60. Haryana is doing 65.
Now I’m waiting for the usual suspects to reply to this (either on twitter, or as a comment on my blog) saying this doesn’t matter we are “not doing enough tests per million”.
I wonder why some people are proud to show off their innumeracy (OK fine, I understand that it’s a bit harsh to describe someone who doesn’t understand Bayes’s Theorem as “innumerate”).
I must warn that this is a super long post. Also I wonder if I should put this on medium in order to get more footage.
Most models of disease spread use what is known as a “SIR” framework. This Numberphile video gives a good primer into this framework.
The problem with the framework is that it’s too simplistic. It depends primarily on one parameter “R0”, which is the average number of people that each infected patient infects. When R0 is high, each patient infects a number of other people, and the disease spreads fast. With a low R0, the disease spreads slow. It was the SIR model that was used to produce all those “flatten the curve” pictures that we were bombarded with a week or two back.
There is a second parameter as well – the recovery or removal rate. Some diseases are so lethal that they have a high removal rate (eg. Ebola), and this puts a natural limit on how much the disease can spread, since infected people die before they can infect too many people.
In any case, such modelling is great for academic studies, and post-facto analyses where R0 can be estimated. As we are currently in the middle of an epidemic, this kind of simplistic modelling can’t take us far. Nobody has a clue yet on what the R0 for covid-19 is. Nobody knows what proportion of total cases are asymptomatic. Nobody knows the mortality rate.
And things are changing well-at-a-faster-rate. Governments are imposing distancing of various forms. First offices were shut down. Then shops were shut down. Now everything is shut down, and many of us have been asked to step out “only to get necessities”. And in such dynamic and fast-changing environments, a simplistic model such as the SIR can only take us so far, and uncertainty in estimating R0 means it can be pretty much useless as well.
In this context, I thought I’ll simulate a few real-life situations, and try to model the spread of the disease in these situations. This can give us an insight into what kind of services are more dangerous than others, and how we could potentially “get back to life” after going through an initial period of lockdown.
The basic assumption I’ve made is that the longer you spend with an infected person, the greater the chance of getting infected yourself. This is not an unreasonable assumption because the spread happens through activities such as sneezing, touching, inadvertently dropping droplets of your saliva on to the other person, and so on, each of which is more likely the longer the time you spend with someone.
Some basic modelling revealed that this can be modelled as a sort of negative exponential curve that looks like this.
T is the number of hours you spend with the other person. is a parameter of transmission – the higher it is, the more likely the disease with transmit (holding the amount of time spent together constant).
The function looks like this:
We have no clue what is, but I’ll make an educated guess based on some limited data I’ve seen. I’ll take a conservative estimate and say that if an uninfected person spends 24 hours with an infected person, the former has a 50% chance of getting the disease from the latter.
This gives the value of to be 0.02888 per hour. We will now use this to model various scenarios.
Delivery
This is the simplest model I built. There is one shop, and N customers. Customers come one at a time and spend a fixed amount of time (1 or 2 or 5 minutes) at the shop, which has one shopkeeper. Initially, a proportion of the population is infected, and we assume that the shopkeeper is uninfected.
And then we model the transmission – based on our , for a two minute interaction, the probability of transmission is %.
In hindsight, I realised that this kind of a set up better describes “delivery” than a shop. With a 0.1% probability the delivery person gets infected from an infected customer during a delivery. With the same probability an infected delivery person infects a customer. The only way the disease can spread through this “shop” is for the shopkeeper / delivery person to be uninfected.
How does it play out? I simulated 10000 paths where one guy delivers to 1000 homes (maybe over the course of a week? that doesn’t matter as long as the overall infected rate in the population otherwise is constant), and spends exactly two minutes at each delivery, which is made to a single person. Let’s take a few cases, with different base cases of incidence of the disease – 0.1%, 0.2%, 0.5%, 1%, 2%, 5%, 10%, 20% and 50%.
The number of NEW people infected in each case is graphed here (we don’t care how many got the disease otherwise. We’re modelling how many got it from our “shop”). The right side graph excludes the case of zero new infections, just to show you the scale of the problem.
Notice this – even when 50% of the population is infected, as long as the shopkeeper or delivery person is not initially infected, the chances of additional infections through 2-minute delivery are MINUSCULE. A strong case for policy-makers to enable delivery of all kinds, essential or inessential.
2. SHOP
Now, let’s complicate matters a little bit. Instead of a delivery person going to each home, let’s assume a shop. Multiple people can be in the shop at the same time, and there can be more than one shopkeeper.
Let’s use the assumptions of standard queueing theory, and assume that the inter-arrival time for customers is guided by an Exponential distribution, and the time they spend in the shop is also guided by an Exponential distribution.
At the time when customers are in the shop, any infected customer (or shopkeeper) inside can infect any other customer or shopkeeper. So if you spend 2 minutes in a shop where there is 1 infected person, our calculation above tells us that you have a 0.1% chance of being infected yourself. If there are 10 infected people in the shop and you spend 2 minutes there, this is akin to spending 20 minutes with one infected person, and you have a 1% chance of getting infected.
Let’s consider two or three scenarios here. First is the “normal” case where one customer arrives every 5 minutes, and each customer spends 10 minutes in the shop (note that the shop can “serve” multiple customers simultaneously, so the queue doesn’t blow up here). Again let’s take a total of 1000 customers (assume a 24/7 open shop), and one shopkeeper.
Notice that there is significant transmission of infection here, even though we started with 5% of the population being infected. On average, another 3% of the population gets infected! Open supermarkets with usual crowd can result in significant transmission.
Does keeping the shop open with some sort of social distancing (let’s see only one-fourth as many people arrive) work? So people arrive with an average gap of 20 minutes, and still spend 10 minutes in the shop. There are still 10 shopkeepers. What does it look like when we start with 5% of the people being infected?
The graph is pretty much identical so I’m not bothering to put that here!
3. Office
This scenario simulates for N people who are working together for a certain number of hours. We assume that exactly one person is infected at the beginning of the meeting. We also assume that once a person is infected, she can start infecting others in the very next minute (with our transmission probability).
How does the infection grow in this case? This is an easier simulation than the earlier one so we can run 10000 Monte Carlo paths. Let’s say we have a “meeting” with 40 people (could just be 40 people working in a small room) which lasts 4 hours. If we start with one infected person, this is how the number of infected grows over the 4 hours.
The spread is massive! When you have a large bunch of people in a small closed space over a significant period of time, the infection spreads rapidly among them. Even if you take a 10 person meeting over an hour, one infected person at the start can result in an average of 0.3 other people being infected by the end of the meeting.
10 persons meeting over 8 hours (a small office) with one initially infected means 3.5 others (on average) being infected by the end of the day.
Offices are dangerous places for the infection to spread. Even after the lockdown is lifted, some sort of work from home regulations need to be in place until the infection has been fully brought under control.
4. Conferences
This is another form of “meeting”, except that at each point in time, people don’t engage with the whole room, but only a handful of others. These groups form at random, changing every minute, and infection can spread only within a particular group.
Let’s take a 100 person conference with 1 initially infected person. Let’s assume it lasts 8 hours. Depending upon how many people come together at a time, the spread of the infection rapidly changes, as can be seen in the graph below.
If people talk two at a time, there’s a 63% probability that the infection doesn’t spread at all. If they talk 5 at a time, this probability is cut by half. And if people congregate 10 at a time, there’s only a 11% chance that by the end of the day the infection HASN’T propagated!
One takeaway from this is that even once offices start functioning, they need to impose social distancing measures (until the virus has been completely wiped out). All large-ish meetings by video conference. A certain proportion of workers working from home by rotation.
Over ten years ago, I wrote this blog post that I had termed as a “lazy post” – it was an email that I’d written to a mailing list, which I’d then copied onto the blog. It was triggered by someone on the group making an off-hand comment of “doing regression analysis”, and I had set off on a rant about why the misuse of statistics was a massive problem.
Ten years on, I find the post to be quite relevant, except that instead of “statistics”, you just need to say “machine learning” or “data science”. So this is a truly lazy post, where I piggyback on my old post, to talk about the problems with indiscriminate use of data and models.
I had written:
there is this popular view that if there is data, then one ought to do statistical analysis, and draw conclusions from that, and make decisions based on these conclusions. unfortunately, in a large number of cases, the analysis ends up being done by someone who is not very proficient with statistics and who is basically applying formulae rather than using a concept. as long as you are using statistics as concepts, and not as formulae, I think you are fine. but you get into the “ok i see a time series here. let me put regression. never mind the significance levels or stationarity or any other such blah blah but i’ll take decisions based on my regression” then you are likely to get into trouble.
The modern version of this is – everybody wants to do “big data” and “data science”. So if there is some data out there, people will want to draw insights from it. And since it is easy to apply machine learning models (thanks to open source toolkits such as the scikit-learn package in Python), people who don’t understand the models indiscriminately apply it on the data that they have got. So you have people who don’t really understand data or machine learning working with those, and creating models that are dangerous.
As long as people have idea of the models they are using, and the assumptions behind them, and the quality of data that goes into the models, we are fine. However, we are increasingly seeing cases of people using improper or biased data and applying models they don’t understand on top of them, that will have impact that affect the wider world.
So the problem is not with “artificial intelligence” or “machine learning” or “big data” or “data science” or “statistics”. It is with the people who use them incorrectly.
In his excellent podcast episode with EconTalk’s Russ Roberts, psychologist Gerd Gigerenzer introduces the concept of “fast and frugal trees“. When someone needs to make decisions quickly, Gigerenzer says, they don’t take into account a large number of factors, but instead rely on a small set of thumb rules.
The podcast itself is based on Gigerenzer’s 2009 book Gut Feelings. Based on how awesome the podcast was, I read the book, but found that it didn’t offer too much more than what the podcast itself had to offer.
Coming back to fast and frugal trees..
In recent times, ever since “big data” became a “thing” in the early 2010s, it is popular for companies to tout the complexity of their decision algorithms, and machine learning systems. An easy way for companies to display this complexity is to talk about the number of variables they take into account while making a decision.
For example, you can have “fin-tech” lenders who claim to use “thousands of data points” on their prospective customers’ histories to determine whether to give out a loan. A similar number of data points is used to evaluate resumes and determine if a candidate should be called for an interview.
With cheap data storage and compute power, it has become rather fashionable to “use all the data available” and build complex machine learning models (which aren’t that complex to build) for decisions that were earlier made by humans. The problem with this is that this can sometimes result in over-fitting (system learning something that it shouldn’t be learning) which can lead to disastrous predictive power.
In his podcast, Gigerenzer talks about fast and frugal trees, and says that humans in general don’t use too many data points to make their decisions. Instead, for each decision, they build a quick “fast and frugal tree” and make their decision based on their gut feelings about a small number of data points. What data points to use is determined primarily based on their experience (not cow-like experience), and can vary by person and situation.
The advantage of fast and frugal trees is that the model is simple, and so has little scope for overfitting. Moreover, as the name describes, the decision process is rather “fast”, and you don’t have to collect all possible data points before you make a decision. The problem with productionising the fast and frugal tree, however, is that each user’s decision making process is different, and about how we can learn that decision making process to make the most optimal decisions at a personalised level.
How you can learn someone’s decision-making process (when you’ve assumed it’s a fast and frugal tree) is not trivial, but if you can figure it out, then you can build significantly superior recommender systems.
If you’re Netflix, for example, you might figure that someone makes their movie choices based only on age of movie and its IMDB score. So their screen is customised to show just these two parameters. Someone else might be making their decisions based on who the lead actors are, and they need to be shown that information along with the recommendations.
Another book I read recently was Todd Rose’s The End of Average. The book makes the powerful point that nobody really is average, especially when you’re looking a large number of dimensions, so designing for average means you’re designing for nobody.
I imagine that is one reason why a lot of recommender systems (Netflix or Amazon or Tinder) fail is that they model for the average, building one massive machine learning system, rather than learning each person’s fast and frugal tree.
The latter isn’t easy, but if it can be done, it can result in a significantly superior user experience!
A long time back I had used a primitive version of my Single Malt recommendation app to determine that I’d like Ardbeg. Presently, the wife was travelling to India from abroad, and she got me a bottle. We loved it.
And so I had screenshots from my app stored on my phone all the time, to be used while at duty frees, so I would know what whiskies to buy.
And then about a year back, we started planning a visit to Scotland. If you remember, we were living in London then, and my wife’s cousin and her family were going to visit us over Christmas. And the plan was to go to the Scottish Highlands for a few days. And that had to include a distillery tour.
Out came my app again, to determine which distillery to visit. I had made a scatter plot (which I have unfortunately lost since) with the distance from Inverness (where we were going to be based) on one axis, and the likelihood of my wife and I liking a whisky (based on my app) on the other (by this time, Ardbeg was firmly in the “calibration set”).
The clear winner was Clynelish – it was barely 100 kilometers away from Inverness, promised a nice drive there, and had a very high similarity score to the stuff that we liked. I presently called them to make a booking for a distillery tour. The only problem was that it’s a Diageo distillery, and Diageo distillery doesn’t allow kids inside (we were travelling with three of them).
I was proud of having planned my vacation “using data science”. I had made up a blog post in my head that I was going to write after the vacation. I was basically picturing “turning around to the umpire and shouting ‘howzzat'”. And then my hopes were dashed.
A week after I had made the booking, I got a call back from the distillery informing me that it was unfortunately going to be closed during our vacation, and so we couldn’t visit. My heart sank. We finally had to make do with two distilleries that were pretty close to Inverness, but which didn’t rate highly according to my app.
My cousin-in-law-in-law and I first visited Glen Ord, another Diageo distillery, leaving our wives and kids back in the hotel. The tour was nice, but the whisky at the distillery was rather underwhelming. The high point was the fact that Glen Ord also supplies highly peated malt to other Diageo distilleries such as Clynelish (which we couldn’t visit) and Talisker (one of my early favourites).
A day later, we went to the more family friendly Tomatin distillery, to the south of Inverness (so we could carry my daughter along for the tour. She seemed to enjoy it. The other kids were asleep in the car with their dad). The tour seemed better there, but their flagship whisky seemed flat. And then came Cu Bocan, a highly peated whisky that they produce in very limited quantities and distribute in a limited fashion.
Initially we didn’t feel anything, but then the “smoke hit from the back”. Basically the initial taste of the whisky was smooth, but as you swallowed it, the peat would hit you. It was incredibly surreal stuff. We sat at the distillery’s bar for a while downing glasses full of Cu Bocan.
The cousin-in-law-in-law quickly bought a bottle to take back to Singapore. We dithered, reasoning we could “use Amazon to deliver it to our home in London”. The muhurta for the latter never arrived, and a few months later we were on our way to India. Travelling with six suitcases and six handbags and a kid meant that we were never going to buy duty free stuff on our way home (not that Cu Bocan was available in duty free).
In any case, Clynelish is also not widely available in duty free shops, so we couldn’t have that as well for a long time. And then we found an incredibly well stocked duty free shop in Maldives, on our way back from our vacation there in August. A bottle was duly bought.
And today the auspicious event arrived for the bottle to be opened. And it’s spectacular. A very different kind of peat than Lagavulin (a bottle of which we just finished yesterday). This one hits the mouth from both the front and the back.
And I would like to call Clynelish the “new big data whisky”, having discovered it through my app, almost going there for a distillery tour, and finally tasting it a year later.
Highly recommended! And I’d highly recommend my app as well!
For best results, use machine learning to do customer segmentation, but then get humans with domain knowledge to validate the segments
There are two common ways in which people do customer segmentation. The “traditional” method is to manually define the axes through which the customers will get segmented, and then simply look through the data to find the characteristics and size of each segment.
Then there is the “data science” way of doing it, which is to ignore all intuition, and simply use some method such as K-means clustering and “do gymnastics” with the data and find the clusters.
A quantitative extreme of this method is to do gymnastics with your data, get segments out of it, and quantitatively “take action” on it without really bothering to figure out what each clusters represent. Loosely speaking, this is how a lot of recommendation systems nowadays work – some algorithm somewhere finds people similar to you based on your behaviour, and recommends to you what they liked.
I usually prefer a sort of middle ground. I like to let the algorithms (k-means easily being my favourite) to come up with the segments based on the data, and then have a bunch of humans look at the segments and make sense of it.
Basically whatever segments are thrown up by the algorithm need to be validated by human intuition. Getting counterintuitive clusters is also not a problem – on several occasions, people I’ve validated the clusters by (usually clients) have used the counterintuitive clusters to discover bugs, gaps in the data or patterns that they didn’t know of earlier.
Also, in terms of validation of clusters, it is always useful to get people with domain knowledge to validate the clusters. And this also means that whatever clusters you’ve generated you are able to represent them in a human-readable format. The best way of doing that is to use the cluster centres and then represent them somehow in a “physical” manner.
I started writing this post some three days ago and am only getting to finish it now. Unfortunately, in the meantime I’ve forgotten the exact motivation of why I started writing this. If i recall that, I’ll maybe do another post.

web.jpg)





 is a parameter of transmission – the higher it is, the more likely the disease with transmit (holding the amount of time spent together constant).
is a parameter of transmission – the higher it is, the more likely the disease with transmit (holding the amount of time spent together constant).
 of the population is infected, and we assume that the shopkeeper is uninfected.
of the population is infected, and we assume that the shopkeeper is uninfected.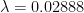 , for a two minute interaction, the probability of transmission is
, for a two minute interaction, the probability of transmission is 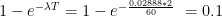 %.
%.





{kind=link}