Finally, many months after other Indian states had conducted a similar exercise, Karnataka released the results of its first “covid-19 sero survey” earlier this week. The headline number being put out is that about 27% of the state has already suffered from the infection, and has antibodies to show for it. From the press release:
Out of 7.07 crore estimated populationin Karnataka, the study estimates that 1.93 crore (27.3%) of the people are either currently infected or already had the infection in the past, as of 16 September 2020.
To put that number in context, as of 16th September, there were a total of 485,000 confirmed cases in Karnataka (official statistics via covid19india.org), and 7536 people had died of the disease in the state.
It had long been estimated that official numbers of covid-19 cases are off by a factor of 10 or 20 – that the actual number of people who have got the disease is actually 10 to 20 times the official number. The serosurvey, assuming it has been done properly, suggests that the factor (as of September) is 40!
If the ratio has continued to hold (and the survey accurate), nearly one in two people in Karnataka have already got the disease! (as of today, there are 839,000 known cases in Karnataka)
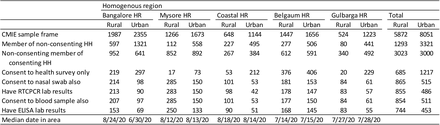
Of course, there are regional variations, though I should mention that the smaller the region you take, the less accurate the survey will be (smaller sample size and all that). In Bangalore Urban, for example, the survey estimates that 30% of the population had been infected by mid-September. If the ratio holds, we see that nearly 60% of the population in the city has already got the disease.
The official statistics (separate from the survey) also suggest that the disease has peaked in Karnataka. In fact, it seems to have peaked right around the time the survey was being conducted, in September. In September, it was common to see 7000-1000 new cases confirmed in Karnataka each day. That number has come down to about 3000 per day now.
Now, there are a few questions we need to answer. Firstly – is this factor of 40 (actual cases to known cases) feasible? Based on this data point, it makes sense:
In May, when Karnataka had a very small number of “native cases” and was aggressively testing everyone who had returned to the state from elsewhere, a staggering 93% of currently active cases were asymptomatic. In other words, only 1 in 14 people who was affected was showing any sign of symptoms.
Then, as I might have remarked on Twitter a few times, compulsory quarantining or hospitalisation (which was in force until July IIRC) has been a strong disincentive to people from seeking medical help or getting tested. This has meant that people get themselves tested only when the symptoms are really clear, or when they need attention. The downside of this, of course, has been that many people have got themselves tested too late for help. One statistic I remember is that about 33% of people who died of covid-19 in hospitals died within 24 hours of hospitalisation.
So if only one in 14 show any symptoms, and only those with relatively serious symptoms (or with close relatives who have serious symptoms) get themselves tested, this undercount by a factor of 40 can make sense.
Then – does the survey makes sense? Is 15000 samples big enough for a state of 70 million? For starters, the population of the state doesn’t matter. Rudimentary statistics (I always go to this presentation by Rajeeva Karandikar of CMI) tells us that the size of the population doesn’t matter. As long as the sample has been chosen randomly, all that matters for the accuracy of the survey is the size of the sample. And for a binary decision (infected / not), 15000 is good enough as long as the sample has been random.
And that is where the survey raises questions – the survey has used an equal number of low risk, high risk and medium risk samples. “High risk” have been defined as people with comorbidities. Moderate risk are people who interact a lot with a lot of people (shopkeepers, healthcare workers, etc.). Both seem fine. It’s the “low risk” that seems suspect, where they have included pregnant women and attendants of outpatient patients in hospitals.
I have a few concerns – are the “low risk” low risk enough? Doesn’t the fact that you have accompanied someone to hospital, or gone to hospital yourself (because you are pregnant), make you higher than average risk? And then – there are an equal number of low risk, medium risk and high risk people in the sample and there doesn’t seem to be any re-weighting. This suggests to me that the medium and high risk people have been overrepresented in the sample.
Finally, the press release says:
We excluded those already diagnosed with SARS-CoV2 infection, unwilling to provide a sample for the test, or did not agree to provide informed consent
I wonder if this sort of exclusion doesn’t result in a bias in itself.
Putting all this together – that there are qual samples of low, medium and high risk, that the “low risk” sample itself contains people of higher than normal risk, and that people who have refused to participate in the survey have been excluded – I sense that the total prevalence of covid-19 in Karnataka is likely to be overstated. By what factor, it is impossible to say. Maybe our original guess that the incidence of the disease is about 20 times the number of known cases is still valid? We will never know.
Nevertheless, we can be confident that a large section of the state (may not be 50%, but maybe 40%?) has already been infected with covid-19 and unless the ongoing festive season plays havoc, the number of cases is likely to continue dipping.
However, this is no reason to be complacent. I think Nitin Pai is bang on here.
And I know a lot of people who have been aggressively social distancing (not even meeting people who have domestic help coming home, etc.). It is important that when they do relax, they do so in a graded manner.
Wear masks. Avoid crowded closed places. If you are going to get covid-19 anyway (and many of us have already got it, whether we know it or not), it is significantly better for you that you get a small viral load of it.