Not often that I comment on User Interface, but this has a quantitative aspect to it, so I thought I’ll write about it. Basically it’s with the use of sliders on websites that you move around to determine an amount or a limit.
More specifically, I’m in the process of planning an extended weekend in Bali next month (the wife is going to be based in Jakarta for two months starting this weekend), and checking out sites such as TripAdvisor and AirBnB for accommodation. This necessarily means using a slider to determine my maximum willingness to pay for a room.
The problem with such sliders is that they’re linear. So for example, on the Travelmob page where I’m looking for villas, the price per night varies from Rs. 650 to Rs. 65000, or a factor of 100. And the slider uses a linear scale. So considering that I consider about Rs. 3500 per night as my budget, in order to set that budget I have to move the right slider (my maximum willingness to pay) way over to the left, till it almost coincides with the left slider (which determines the minimum price). And considering the small distance between the two sliders, it is easy go wrong and not be precise on your limits. A rather frustrating experience!
Instead, if the slider were to use a logarithmic scale, then 6500 would be the midpoint (geometric average of minimum and maximum), and that would allow me to pull the slider to 3500 without much hassle, improving my experience!
But then I suspect the current poor design is by design – by making it hard for you to move sliders down to low prices, maybe they are nudging customers to go for higher priced rooms?
On a different note, while on the topic of sliders, there are “fin-tech” startups that determine whether you are good credit depending upon things like the amount of time you spend moving around a slider to determine how much money you want to borrow. Quoting from Sangeet’s blog:
As an example, most peer lending platforms have a slider allowing the borrower to decide what loan they would like to take. In an excellent whitepaper by Foundation Capital on the state of peer lending, Charles Moldow shares that the longer a borrower spends moving the slider up and down (and hence, potentially, debating her ability to return the loan), the more likely is she to return the loan. Such correlations help platforms improve their ability to curate participants over time.

This slider also looks linear, rather than logarithmic! And so it goes.
Update
AirBnB actually uses a logarithmic slider! Whatay!
Let’s assume for a moment we are dealing with continuous variables.
Linear scale is best suited for a uniform distribution in which the probability of a value belonging to a small region around each point is equal. It is obvious that linear scale is not optimal if the distribution of the variable is non-uniform. But we can use a fundamental property in statistics: if X has the CDF F, then the distribution of F(X) is the standard uniform distribution. The proof is simple. X has the CDF F => Pr( X < x ) = F( x ). As F is [weakly] monotonic, Pr( X < x ) = Pr( F(X) < F(x) ). Assume F(x) = u where 0 <= u <= 1. Then Pr( F(X) < u ) = u which is the definition of the standard uniform distribution. This property is also the basis behind generation of random numbers from any distribution using the method of inversion, in which first one generates uniform random variates from the standard uniform distribution U(0,1) and then takes the inverse CDF transformation.
Armed with this property, we can reason when a log-scale make perfect sense. The obvious answer is when the distribution of log of a random variable is uniform. This happens when the PDF of the (bounded) variable is 1/(x*(b-a)). This can be proved as follows. Let X have the distribution such that Y = log X is uniform. This means that F(y) = P(Y < y) = ( y – a ) / (b – a), where F is the CDF, and a and b are parameters of the uniform distribution with a < b. Now let y = log x. Then F( x ) = P ( X < x ) = P( log X < log x) = P(Y < y) = (log x – a) / (b – a). On differentiation we get the pdf f( x ) = 1/(x*(b-a)). P ( X < x ) = P( log X < log x) as the logarithmic function is monotonic. In other words if we have a distribution where the likelihood of observing a value in a small range around x becomes around half on doubling x, then log-scale is the perfect or natural scale to use.
Generalizing this, the ideal scale for any continuous distribution would be the "CDF scale", i.e. using the transform F( X ) as that is linear by definition. So if the distribution of prices is normal, use the error function scale.
In the discrete world, use the CDF scale of the closest continuous distribution.
just testing if beautiful math works here.
so what you’re saying is that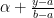 (please ignore).
(please ignore).
Coming to more serious stuff: things like hotel room rates can be modelled as some sort of an exponential distribution, or even power law. In such cases, logarithmic scale surely makes sense.
Yes, log scale makes does sense for exponential distribution, but it does not appear to be the optimal scale (if you will) if the data truly follows exponential distribution. I do not have the theory but R simulations for sample lamba values show log scale seems to result in left-skewed distribution for exponential data – so extreme left regions of the slider may correspond to too few points.
This is what I tried in R
lambda <- 1
N <- 10000
x <- rexp( N, lambda )
par( mfrow=c(1,2) )
plot( density( log( x ) ), main=’Density of log x’, sub=’x is exponential, lambda=1′ )
plot( density( 1 – exp( -lambda * x ) ), main=’Density of 1 – exp(-lambda x)’, sub=’x is exponential, lambda=1′ )
lambda <- 0.5
N <- 10000
x <- rexp( N, lambda )
par( mfrow=c(1,2) )
plot( density( log( x ) ), main=’Density of log x’, sub=’x is exponential, lambda=0.5′ )
plot( density( 1 – exp( -lambda * x ) ), main=’Density of 1 – exp(-lambda x)’, sub=’x is exponential, lambda=0.5′ )
So here we go the Leslie Lamport way for the math
If has the CDF
has the CDF  , then the distribution of
, then the distribution of  is the standard uniform distribution
is the standard uniform distribution  . The proof is simple.
. The proof is simple.  has the CDF
has the CDF  is the same as saying $latex P( X < x ) = F( x )$. As $latex F$ is [weakly] monotonic, $latex P( X < x ) = P[ F(X) < F(x) ]$. Assume $latex F(x) = u$ where $latex u \in (0,1]$. Then $latex P( F(X) < u ) = u$ which is by definition the standard uniform distribution.
This happens when the PDF of the (bounded) variable is $latex \frac{1}{x \ (b-a)}$. This can be proved as follows. Let $latex X$ have the distribution such that $latex Y = \log X$ is uniform. This means that $latex F(y) = P(Y < y) = $ $latex \frac{y-a}{b-a}$, where $latex F$ is the CDF, and $latex a$ and $latex b$ are parameters of the uniform distribution with $latex a < b$. Now let $latex y = \log x$. Then $latex F( x ) = P ( X < x ) = P( \log X < \log x) = P(Y < y) = \frac{\log x - a}{b - a}$. On differentiation we get the pdf $latex f( x ) = \frac{1}{x \ (b-a)}$.
is the same as saying $latex P( X < x ) = F( x )$. As $latex F$ is [weakly] monotonic, $latex P( X < x ) = P[ F(X) < F(x) ]$. Assume $latex F(x) = u$ where $latex u \in (0,1]$. Then $latex P( F(X) < u ) = u$ which is by definition the standard uniform distribution.
This happens when the PDF of the (bounded) variable is $latex \frac{1}{x \ (b-a)}$. This can be proved as follows. Let $latex X$ have the distribution such that $latex Y = \log X$ is uniform. This means that $latex F(y) = P(Y < y) = $ $latex \frac{y-a}{b-a}$, where $latex F$ is the CDF, and $latex a$ and $latex b$ are parameters of the uniform distribution with $latex a < b$. Now let $latex y = \log x$. Then $latex F( x ) = P ( X < x ) = P( \log X < \log x) = P(Y < y) = \frac{\log x - a}{b - a}$. On differentiation we get the pdf $latex f( x ) = \frac{1}{x \ (b-a)}$.
This gives me the idea of a “percentile slider”, where the slider is “non-parametric” and the middle of the slider represeents the median value, and so on. The problem with this slider is that it may not be intuitive and gradients at different parts of the slider may be different, and without a pattern.
But the advantage is that it is not dependent on the underlying distribution!